An Introduction to
Computer Vision& Image Processing
A deep, bilingual study companion — from the goal of vision and the human eye, through pinhole geometry, lenses, image sensors, binary images, convolution filters, and the frequency domain.
دليل مذاكرة عميق ثنائي اللغة — من هدف الرؤية الحاسوبية والعين البشرية، مروراً بالثقب الضيق والعدسات والمستشعرات والصور الثنائية، وصولاً إلى الالتفاف والمرشحات والمجال الترددي.
The goal: to make computers understand and analyze visual content the same way humans do.
الهدف: جعل الحاسوب يفهم ويحلّل المحتوى البصري كما يفعل الإنسان.
Three complementary one-line definitions to memorize:
Vision is automating human visual processes.الرؤية هي أتمتة العمليات البصرية البشرية.
Vision is an information-processing task.الرؤية مهمة معالجة معلومات.
Vision is inverting image formation.الرؤية هي عكس عملية تكوين الصورة — أي استرجاع معلومات المشهد من الصورة ثنائية الأبعاد، وقد يشمل ذلك البنية ثلاثية الأبعاد.
The four sub-areas of Computer Vision
The field decomposes into four canonical problems — memorize them in order, since later courses follow the same progression:
Imaging — how images are formed (pinhole, lenses, sensors). التصوير: كيف تتشكّل الصورة.
Features and boundaries — extracting edges, corners, regions. السمات والحدود: استخراج الحواف والزوايا والمناطق.
3D reconstruction — recovering 3D structure from 2D images. إعادة البناء ثلاثي الأبعاد: استرجاع البنية ثلاثية الأبعاد من صور ثنائية الأبعاد.
Visual perception — high-level recognition, scene understanding. الإدراك البصري: التعرّف والفهم على مستوى عالٍ للمشهد.
Computer: Camera (sensor) → Vision software (interpreter) → same output, in text.
Figure 1 · The shared architecture of biological and artificial vision systems.
📜 Historical milestones — A timeline you should know
1957: Russell Kirsch produces the world's first digitized photograph (a baby's portrait). He famously asked: "What would happen if computers could look at pictures?"
معالم تاريخية: ١٩٥٧ أول صورة رقمية لكيرش، ١٩٦٠ ولادة الحقل، ١٩٧٠ خوارزميات المعالجة الأولية، ١٩٨٠ التصوير ثنائي البعد، أواخر التسعينات OCR وكاميرات ذكية، ومنذ ٢٠١٠ معالجة ثنائية وثلاثية الأبعاد كاملة.
— Part I · cont.
Why build machines that emulate human vision?
لماذا نبني آلات تحاكي الرؤية البشرية؟
Given that the human visual system is so powerful (about 60% of the brain is involved in visual processing!), why bother building artificial ones?
To free up human time for more rewarding activities. لتحرير الوقت لأنشطة أكثر فائدة.
Our vision is not good at precise measurement of the physical world. رؤيتنا ليست جيدة في القياسات الدقيقة.
Machines can surpass human vision — extracting information we simply cannot see (infrared, satellite imagery, microscopy, etc.). الآلات يمكنها تجاوز قدرة الإنسان واستخراج معلومات لا نراها.
Why this matters for the exam
If asked "Why CV given humans already see well?" — give all three reasons. The first is economic (automation), the second is a limitation of biology (precision), and the third is a superpower (going beyond biology). Examiners love this triple structure.
First principles vs. just throwing data at a neural net
المبادئ الأولى مقابل تدريب شبكة عصبية على بيانات ضخمة
A natural question: why not just train a neural network with tons of data? The lecture gives three pointed answers:
It's unnecessary to train a network for a phenomenon that can be precisely described from first principles. لا داعي لتدريب شبكة على ظاهرة يمكن وصفها رياضياً بدقة من المبادئ الأولى.
When a network fails, first principles are the only hope for understanding why. عند فشل الشبكة، المبادئ الأولى هي الأمل الوحيد لفهم السبب.
Models based on first principles can be used to synthesize training data instead of laboriously collecting it. يمكن للنماذج المبنية على المبادئ الأولى توليد بيانات التدريب بدل جمعها.
⚠ Conceptual gotcha
This isn't anti-deep-learning. It's saying: physics + geometry comes first. The pinhole equations you'll learn next are an example — they're exact, interpretable, and you can simulate training data with them.
— Part II · Anatomy of a vision system
A typical computer-vision pipeline
خط أنابيب الرؤية الحاسوبية النموذجي
Memorize this four-stage structure — it appears in almost every exam:
Figure 2 · From raw pixels to decisions, in four stages.
🧪 Expanded breakdown of each stage
Stage 1 — Pre-processing · المعالجة الأولية
Noise reduction, image scaling, color-space conversion, gamma correction. The goal: clean the input.
Stage 2 — Selecting Areas of Interest · اختيار مناطق الاهتمام
Object detection, background subtraction, feature extraction, image segmentation. The goal: find where the interesting stuff is.
Stage 3 — Precise Processing of Selected Areas · المعالجة الدقيقة
Object recognition, tracking, feature matching. The goal: figure out what it is and follow it.
Stage 4 — Decision Making · اتخاذ القرار
Motion analysis, match/no-match, flag events. The goal: act on the result.
Vision is multi-disciplinary
Computer vision lives inside Artificial Intelligence and overlaps with: Machine Learning, Optics, Robotics, Image Preprocessing, Domain Knowledge, and NLP.
الرؤية الحاسوبية حقل متعدد التخصصات: تعلم آلي، بصريات، روبوتات، معالجة صور، معرفة بالمجال، ومعالجة لغات طبيعية.
◇ Vision deals with images — and an image is an array of pixels
Each pixel carries values: brightness, color, distance, material. Up close, the image you find "interesting" is just a grid of numbers (e.g. 157, 159, 159, 104, 104…).
الصورة مصفوفة من البكسلات، وكل بكسل يحمل: السطوع، اللون، البعد، والمادة.
Real-world applications
تطبيقات في العالم الحقيقي
You don't need to memorize all of these, but recognize the categories — exam questions often ask "give 3 applications of CV".
Domain
Examples
What it does
Factory automation
Vision-guided robotics, visual inspection
Robots that see and inspect products on a line
OCR
License-plate reading, digitizing books
Reading text from images
Biometrics
Iris, face detection & recognition, signature
Capture → Extract → Compare → Match
Security
Object detection & tracking, surveillance
Following people/objects over time
Entertainment
Kinect, mocap (Gollum's 964 face points)
Depth sensing, performance capture
AR / VFX
Snapchat filters, face manipulation
Real-time face mesh + warping
Autonomous nav.
Mars rovers, driverless cars
Seeing the world to move through it
Remote sensing
Satellites, Amazon deforestation tracking
Earth observation at scale
Medical imaging
MRI/CT analysis
Diagnosis assistance
Retail
Smart vending machines
Recognizing the customer / product
🎬 The Kinect — a CV system you can name in detail
Microsoft's Kinect (Xbox 360) is a classic exam example. Its sensors include:
RGB camera — color image
IR projector — projects a structured infrared pattern
IR camera — captures the pattern's deformation → produces a depth sensor output
Multi-array microphone — audio (not vision, but completes the picture)
Motorized tilt — mechanical positioning
Combined, this gives RGB + depth ("RGB-D") in real time — enabling full-body motion control in games.
يستخدم Kinect: كاميرا ملونة، باعث أشعة تحت حمراء، كاميرا أشعة تحت حمراء (لاستخراج العمق)، ميكروفون متعدد، ومحرّك للإمالة.
— Part III · How humans actually do it
How do humans do it? — Inside the visual brain
كيف يقوم الإنسان بالرؤية؟ — داخل الدماغ البصري
Vision is easy for us — but we don't fully understand how we do it. About 60% of the brain is involved in visual processing, distributed across many specialized regions:
الرؤية سهلة علينا لكننا لا نفهم كيف نراها فعلياً. حوالي ٦٠٪ من الدماغ يشارك في معالجة الإشارة البصرية، موزعة على مناطق متخصصة.
Region
Function · الوظيفة
LGN (Lateral Geniculate Nucleus)
Relay station from the retina to the cortex. محطة تتابع من الشبكية إلى القشرة.
V1 (Primary Visual Cortex)
Receives all visual input. Begins processing color, motion, and shape. Cells here have the smallest receptive fields.
V2, V3, VP
Continue processing; cells have progressively larger receptive fields.
V3A
Biased for perceiving motion.
V4v
Function unknown.
MT / V5
Detects motion.
V7
Function unknown.
V8
Processes color vision.
LO (Lateral Occipital)
Plays a role in recognizing large-scale objects.
ITC (Inferior Temporal Cortex)
High-level recognition.
Note: A V6 region has been identified only in monkeys, not yet in humans.
▲ Exam-worthy insight
Notice the brain's strategy: specialization. Different regions for color (V8), motion (MT/V5, V3A), and large objects (LO). Computer vision systems often borrow this modular architecture — separate networks for detection, segmentation, recognition.
الدماغ يعتمد التخصّص: مناطق منفصلة للحركة واللون والأجسام الكبيرة. أنظمة الرؤية الحاسوبية تستعير هذه البنية المعيارية.
— Part IV · Why vision is hard
Vision Research — illusions, ambiguities, and the limits of "seeing"
أبحاث الرؤية: الخدع البصرية والغموض وحدود الرؤية
Three statements summarize the state of vision research — they often appear as a short-answer exam item:
Vision is a hard problem.الرؤية مسألة صعبة.
Vision is multi-disciplinary (AI, ML, optics, robotics, NLP, image processing, domain knowledge). الرؤية متعددة التخصصات.
Considerable progress has been made with many successful real-world applications. تحقّق تقدّم كبير مع تطبيقات ناجحة في العالم الحقيقي.
Human vision is fallible
Human vision is more fallible than we may like to believe. We see what we see and believe it to be accurate.
الرؤية البشرية أكثر عرضة للخطأ مما نحب أن نعتقد — نرى ما نرى ونؤمن بأنه دقيق.
Vision research relies heavily on illusions to expose how the brain (and any vision system) infers rather than simply records. Key examples to know:
Fraser's Spiral — appears to be a spiral; is actually concentric circles. حلزون فريزر يبدو حلزونياً وهو في الحقيقة دوائر متراكزة.
Checker Shadow (Adelson) — square A and square B have the same brightness in pixels, but B looks brighter because the brain "discounts" the cylinder's shadow. المربعان A و B بنفس السطوع، لكن الدماغ يصحّح للظل.
Donguri Wave — perceived motion without motion.
Forced Perspective — two people of equal height made to look very different.
Visual ambiguities · الغموض البصري
Different from illusions: ambiguities are images that genuinely admit multiple valid interpretations.
Six cubes or seven? — depending on which faces you treat as "front".
Young-girl / old-woman, face / vase — figure-ground reversal.
Crater on a mound / mound in a crater — flipping the image reverses the perceived depth, because our brain assumes light comes from above.
Seeing vs. Thinking — the Kanizsa Triangle
You see a white triangle that isn't physically there. Your visual system fabricates contours from the Pac-Man-like inducers. This is thinking bleeding into seeing.
مثلث كانيتسا: ندرك مثلثاً أبيض غير موجود فعلياً — التفكير يتسلل إلى الرؤية.
⊕ Optical illusion vision tests
Black-and-white images of (e.g.) a Dalmatian in dappled shade, or a cow's face hidden in patches. They show that recognition is constructive — once you "get it", you can never un-see it. Implication for CV: pure bottom-up pixel matching is insufficient; prior knowledge matters.
— Lecture 02 · Part IV · The Physics of Picture Making
Image Formation
تكوين الصورة
Definition. An image is the projection of a 3D scene onto a 2D plane. To understand vision, we must understand the geometric and photometric relationship between the scene and its image.
الصورة هي إسقاط مشهد ثلاثي الأبعاد على مستوٍ ثنائي الأبعاد، ولفهم الرؤية يجب فهم العلاقة الهندسية والإشعاعية بين المشهد وصورته.
Three sub-topics structure this lecture:
Pinhole and perspective projection.
Image formation using lenses.
Lens-related issues.
▲ The motivating question
If you simply place a screen in front of a 3D scene (e.g. a house), is an image formed?
Yes — but it is not "clear". Every point on the screen receives light from every point of the scene that can see it, so all the rays superpose into a blurry mess. To make it clear, we must restrict which rays reach which point. Enter the pinhole.
لو وضعنا شاشة أمام مشهد، فهل تتكوّن صورة؟ نعم — لكنها غير واضحة. كل نقطة من الشاشة تستقبل ضوءاً من كل نقاط المشهد، فتتراكب الأشعة وتتشوّش. لجعلها واضحة، يجب تقييد الأشعة الواصلة لكل نقطة — وهنا يأتي الثقب الضيق.
The Pinhole Camera
الكاميرا ذات الثقب الضيق
Three key definitions you must be able to state precisely:
Pinhole · الثقب الضيق: an opaque sheet with a tiny hole in it.
Optical axis · المحور البصري: an axis perpendicular to the image plane (passing through the pinhole).
Effective focal length, f · البعد البؤري الفعّال: the distance between the pinhole and the image plane.
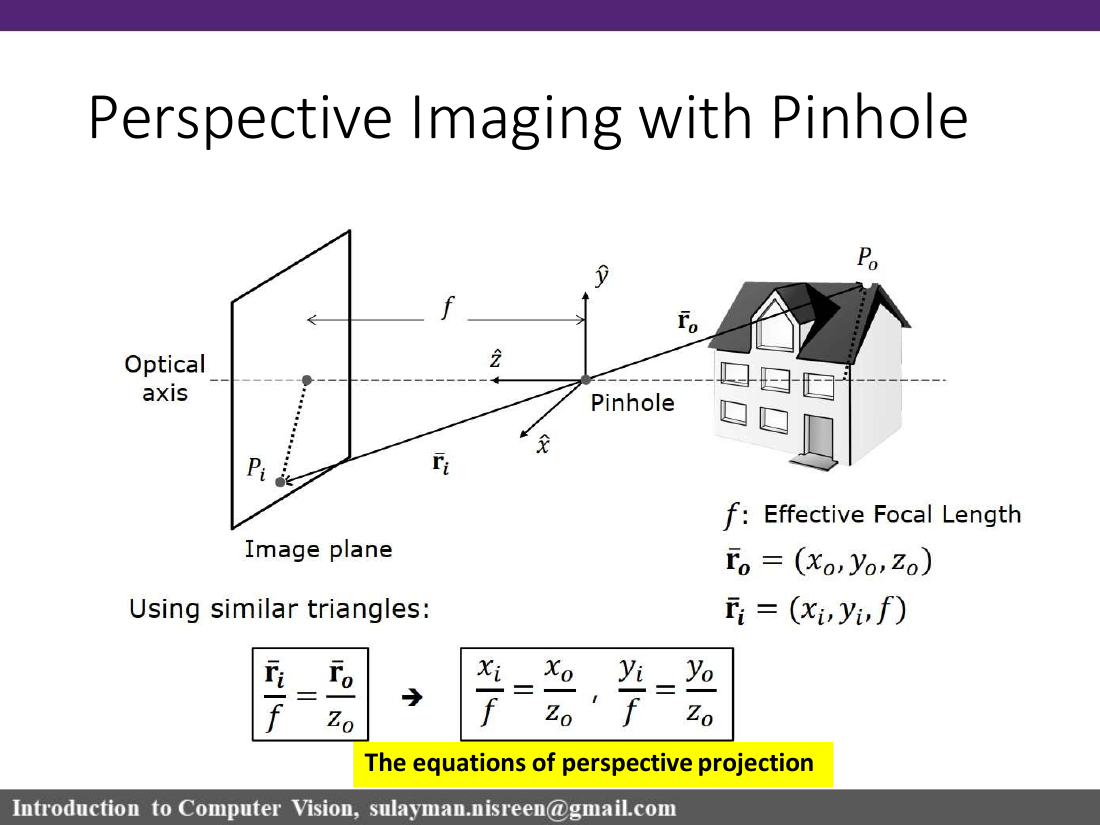
Figure 3 · The pinhole geometry. A ray from scene point P₀ passes through the pinhole and lands at image point Pᵢ on the image plane, distance f behind the pinhole. Note that the image is inverted.
Camera Obscura — the historical pinhole · الغرفة المظلمة
The pinhole camera is the same idea as the camera obscura (literally "dark chamber"). A pinhole in one wall of a darkened room projects an image of the outside scene onto the opposite wall — geometrically accurate enough that Renaissance artists used it as a tracing aid.
الكاميرا ذات الثقب الضيق = camera obscura = "الغرفة المظلمة": كان الفنانون في عصر النهضة يستخدمونها لرسم مشاهد بدقة هندسية.
Perspective Projection — the equations
معادلات الإسقاط المنظوري
Set up coordinates with the origin at the pinhole. Let:
Scene point P₀ at position r̄₀ = (x₀, y₀, z₀)
Image point Pᵢ at position r̄ᵢ = (xᵢ, yᵢ, f) on the image plane.
By similar triangles (the ray from P₀ to Pᵢ passes through the origin):
vector formr̄ᵢ / f = r̄₀ / z₀
Component-wise, this gives the celebrated perspective projection equations:
component form ★xᵢ / f = x₀ / z₀ , yᵢ / f = y₀ / z₀
Or equivalently, solving for the image coordinates:
explicit formxᵢ = f · x₀ / z₀ , yᵢ = f · y₀ / z₀
من تشابه المثلثات نحصل على معادلات الإسقاط المنظوري — الإحداثيتان x و y في الصورة تساويان نظيرتيهما في المشهد مضروبتين بـ f ومقسومتين على العمق z₀.
Sign convention
The slides place the image plane at z = f, so the algebra is written with positive xᵢ and yᵢ. The physical pinhole image is still inverted; some books instead put the real image plane behind the pinhole and introduce a negative sign. For this exam, follow the lecture convention unless a question states otherwise.
Intuition
The further away (larger z₀), the smaller the image — because we're dividing by z₀. The larger the focal length f, the bigger the image. That's why telephoto lenses (large f) magnify distant objects.
Perspective projection of a line
إسقاط مستقيم
Question: what is the perspective projection of a 3D line onto the image plane?
Answer: The image of a 3D line is a line in 2D. Straight lines in the scene map to straight lines in the photograph.
صورة مستقيم في المشهد ثلاثي الأبعاد هي مستقيم في الصورة ثنائية الأبعاد — المستقيمات تبقى مستقيمات.
∴ Why?
Any 3D line together with the pinhole (origin) defines a plane. That plane intersects the image plane in… a line. Done.
— Part V
Image Magnification
تكبير الصورة
Consider a tiny segment A₀B₀ in the scene that lies on a plane parallel to the image plane (so all of it shares the same depth z₀). Let:
A₀ at (x₀, y₀, z₀)
B₀ at (x₀+δx₀, y₀+δy₀, z₀) — displaced by (δx₀, δy₀).
Their images: Aᵢ=(xᵢ, yᵢ), Bᵢ=(xᵢ+δxᵢ, yᵢ+δyᵢ).
From perspective projection applied to both endpoints, and subtracting:
step ①δxᵢ / f = δx₀ / z₀ , δyᵢ / f = δy₀ / z₀
Now magnification is the ratio of image-vector length to scene-vector length:
(m is negative when the image is inverted, which it physically is in a pinhole camera — but the formula is usually stated with absolute value.)
معادلة التكبير الرئيسية: m = f / z₀. التكبير يتناسب طرداً مع البعد البؤري وعكسياً مع العمق.
Consequence: image size is inversely proportional to depth
Closer objects look bigger; far ones look small. This is why train tracks "narrow" toward the horizon and why a forced-perspective trick (e.g. holding someone in your palm) works.
⚠ Two scale regimes
Object size ≪ distance from camera: the whole object lies (essentially) at one depth, so all parts share the same magnification.
Object size ≈ comparable to distance: different parts are at different depths, so they get different magnifications — the object is foreshortened.
إذا كان حجم الجسم صغيراً مقارنةً ببعده، فإنه يخضع لتكبير واحد. أما إذا كان حجمه مقارباً للبعد فأجزاؤه تخضع لتكبيرات مختلفة.
Area magnification
If linear magnification is m, then area scales as m²:
areaAreaᵢ / Area₀ = m²
تكبير المساحة هو مربع التكبير الخطي.
— Part VI
Vanishing Points
نقاط التلاشي
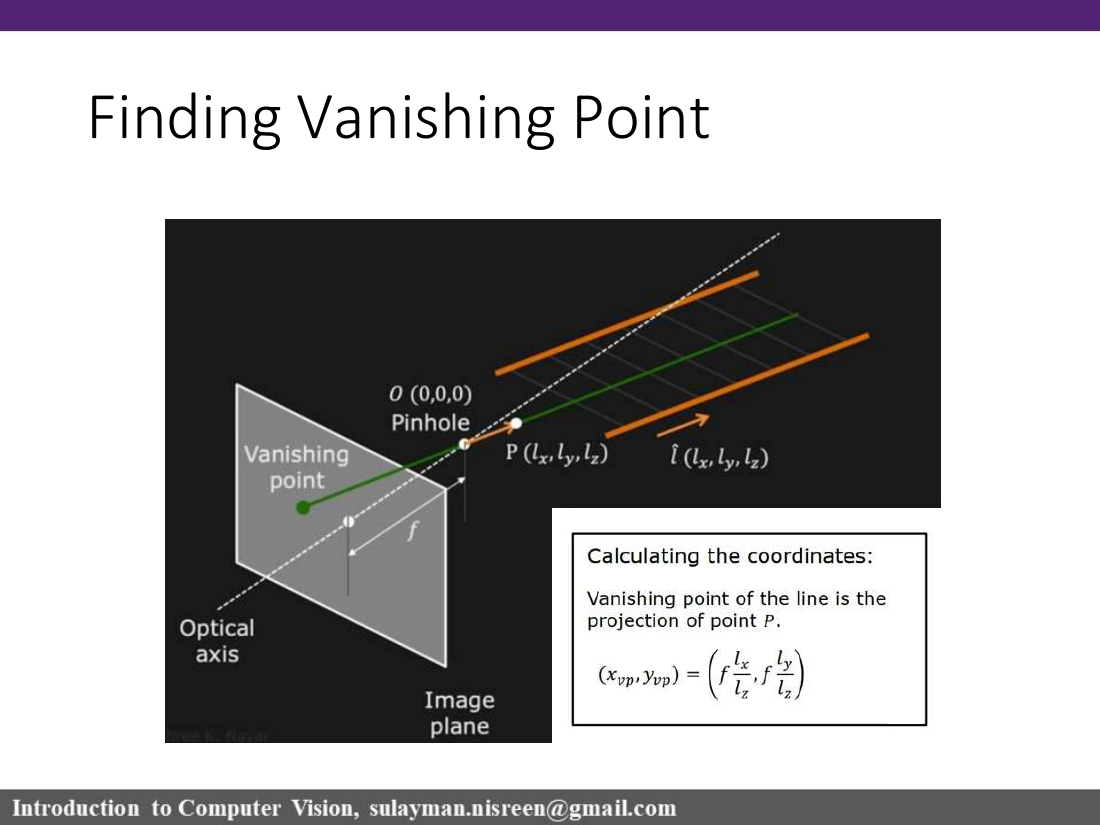
Definition. A vanishing point is the image point where a set of 3D parallel lines appears to disappear / converge.
نقطة التلاشي: النقطة في الصورة التي تتلاقى عندها مجموعة من المستقيمات المتوازية في الفضاء ثلاثي الأبعاد.
Parallel scene lines converge at a single image point — the vanishing point.
The exact location of the vanishing point depends on the orientation of those parallel lines in 3D.
Lines parallel to the image plane have a vanishing point at infinity (they stay parallel in the image).
How to compute the vanishing point — three-step recipe
Define the direction of the parallel lines as a vector ⟨lₓ, l_y, l_z⟩. Since the origin is at the pinhole, this vector also describes a point P on the line through the pinhole that is parallel to the family of lines.
Project P onto the image using the perspective projection equations.
The resulting image point is the vanishing point:
vanishing point ★(x_vp, y_vp) = ( f · lₓ / l_z , f · l_y / l_z )
Figure 4 · The vanishing point is the projection of the direction-vector P. All parallel lines with direction ⟨lₓ, l_y, l_z⟩ converge here on the image plane.
Use of vanishing points in art · في الفن
Vermeer's The Music Lesson (c. 1662–1664) is a textbook example: all the receding edges of the room converge on a single point — used both as a compositional anchor and as evidence that Vermeer may have used a camera obscura.
False perspective · المنظور الكاذب
A corridor in Palazzo Spada (Borromini) appears ~155 ft deep but is actually only ~30 ft. By manipulating where vanishing points fall and how columns scale, the architect tricked the perspective system. Same principle as Hollywood "forced perspective" shots.
المنظور الكاذب: ممر يبدو طوله ١٥٥ قدماً لكنه فعلياً ٣٠ قدماً — خداع لنظام المنظور البصري.
— Part VII
What is the ideal pinhole size?
ما هو الحجم الأمثل للثقب؟
The lecture shows photographs taken with pinholes ranging from 2 mm down to 0.07 mm. Sharpness peaks around 0.35 mm. Why?
Pinhole size
What happens
Result
Too large (e.g. 2 mm, 1 mm)
The hole lets through a bundle of rays from each scene point — each scene point spreads over a small disk on the image.
Blurry (geometric blur).
Optimal (~0.35 mm here)
Geometric blur and diffraction blur balance.
Sharpest possible pinhole image.
Too tiny (e.g. 0.15, 0.07 mm)
Wave optics kicks in: the hole acts as a slit and light diffracts — spreads in waves on the far side.
Blurry again (diffraction blur).
إذا كان الثقب كبيراً جداً تتشوّش الصورة بسبب تراكب الأشعة، وإذا كان صغيراً جداً تتشوّش بسبب الحيود (diffraction). يوجد حجم أمثل في المنتصف.
ideal pinhole diameter ★d ≈ 2·√(f · λ)
where f is effective focal length and λ is the wavelength of light.
Why this formula?
It's the size where the geometric "ray bundle" disk (proportional to d) and the diffraction Airy disk (proportional to f·λ/d) are equal. Setting them equal and solving for d gives d ∝ √(f·λ). The constant happens to be ≈ 2.
Exposure time — and why we need lenses
زمن التعريض — ولماذا نحتاج عدسات
Now the bad news: with a tiny pinhole (the optimal one), only a tiny amount of light reaches the image plane per unit time. So to get a usable, bright image, you must leave the shutter open for a long time.
The lecture's example image of the Flatiron Building is captured with f = 73 mm, d = 0.2 mm, and a 12-second exposure. Twelve seconds is fine for a still building. It's terrible for moving cars, people, or any handheld photograph.
∴ The trade-off — and the solution
Pinhole cameras face a fundamental dilemma: larger holes capture more light (short exposure) but produce blurry images; smaller holes produce sharp images but need impractically long exposures.
This is why we need lenses. A lens can be large (gathers a lot of light → short exposure) yet still focus all the rays from one scene point onto a single image point (sharp image). It gives us the best of both worlds.
المعضلة: الثقب الكبير يجمع ضوءاً كثيراً لكنه يعطي صورة مشوّشة، والصغير يعطي صورة واضحة لكن يحتاج زمن تعريض طويلاً. الحل: العدسة — كبيرة (تجمع ضوءاً) ومركّزة (تعطي صورة حادة).
That trade-off is the cliffhanger for the next lecture (image formation using lenses, lens-related issues).
— Lecture 03 · Image Formation with Lenses
Lenses: brightness without losing geometry
العدسات: ضوء أكثر مع الحفاظ على الإسقاط
A lens performs perspective projection like a pinhole, but gathers significantly more light. The center of the lens plays the role of the pinhole, while the lens bends rays so many rays from one scene point meet again at one image point.
العدسة تعمل مثل الثقب من ناحية الإسقاط المنظوري، لكنها تجمع ضوءاً أكثر بكثير. مركز العدسة يقوم بدور الثقب، والعدسة تكسر الأشعة كي تلتقي في نقطة صورة واحدة.
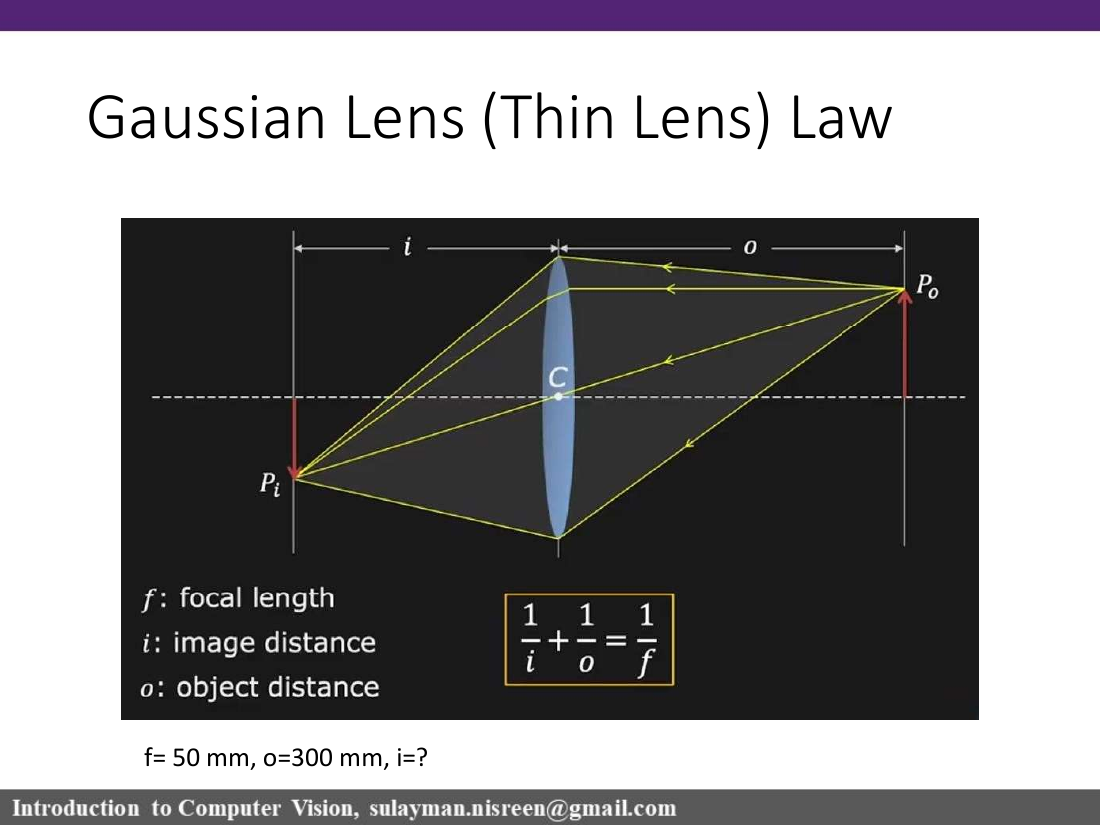
thin lens law ★1/f = 1/o + 1/i
f is focal length, o is object distance, and i is image distance. The slide example asks: if f = 50 mm and o = 300 mm, find i. Compute: 1/i = 1/50 - 1/300 = 5/300 = 1/60, so i = 60 mm.
Focal length
The distance where incoming rays parallel to the optical axis converge. It depends mainly on the lens material's refractive index and the lens shape.
Magnification
For this lecture, lens magnification is image height divided by object height: m = hᵢ/h₀ = i/o. Some optics books add a negative sign for inversion, but the slides use the positive ratio.
Aperture
The aperture D is the clear light-gathering opening of the lens. In N = f/D, D is the aperture diameter/effective opening length.
f-number
The f-number is N = f/D. Small f-number means large aperture and brighter image; large f-number means small aperture and deeper focus.
Setting
Aperture
Brightness
Depth of field
Memory hook
f/5.6
Large
Bright
Shallow
Portrait look: subject sharp, background blur.
f/32
Small
Dim
Deep
Landscape look: more distances acceptably sharp.
two-lens systemm = (i₂/o₂) · (i₁/o₁)
In a two-lens system, the first lens forms an intermediate image and the second lens images that intermediate result. The total magnification is the product of the individual magnifications.
▲ Exam trap
Large f-number does not mean large aperture. Since N = f/D, increasing N means decreasing D when f is fixed. Arabic hint: الرقم كبير، الفتحة صغيرة.
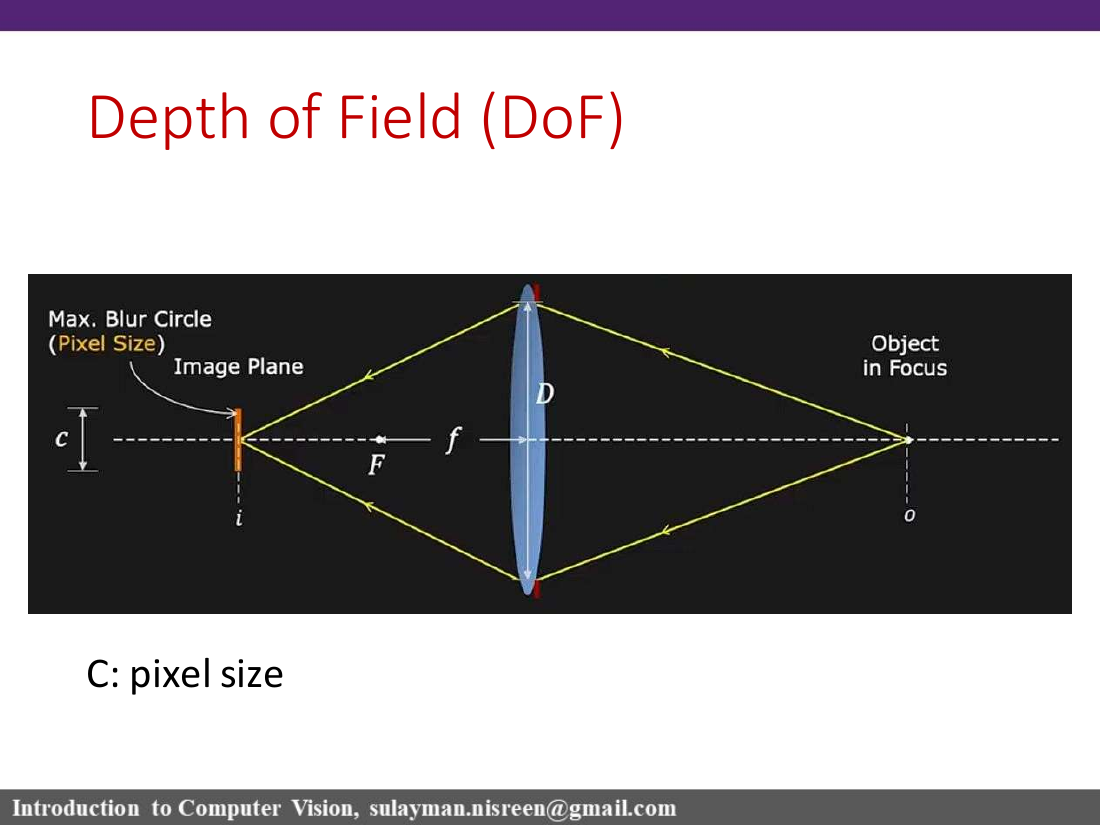
Defocus, blur circle, and depth of field
A lens is focused for one object distance. A point away from the plane of focus does not land as a point on the sensor; it becomes a blur circle. The farther the point is from the focus plane, the larger the blur circle.
Depth of field is the range of object distances over which the image is "sufficiently well focused"; in the lecture, that means the blur is smaller than the finite pixel size C.
عمق المجال هو مجال المسافات التي تبقى فيها الصورة مقبولة الحدة، أي أن دائرة التشوش أصغر من حجم البكسل تقريباً.
There is a trade-off between depth of field and brightness: smaller aperture increases DoF but darkens the image; larger aperture brightens the image but reduces DoF.
Blocking part of the lens
Blocking part of a lens usually darkens the whole image more than it crops a corner, because many rays from each scene point pass through different parts of the lens and still meet at the focused image point. This is the same intuition behind the tissue-box camera demo: the lens gathers bundles of rays while preserving the projection geometry.
Tilted lenses and the plane of focus
Normally the lens plane, sensor plane, and focus plane are parallel. With a tilt-lens camera, the plane of focus can be tilted to match a slanted object, such as a model train. This is the idea behind Scheimpflug adapters and tilt-shift photography.
إمالة العدسة تغيّر مستوي التركيز، فتجعل جسماً مائلاً كاملاً حاداً بدل أن يكون جزء واحد فقط في التركيز.
— Lecture 03 · cont.
Lens-related issues
مشاكل العدسات
Real lenses are imperfect. It is challenging to create an image with the same quality across the whole image plane, so lenses often need compound designs: multiple lens elements with different shapes and materials compensate for one another's defects.
Issue
What it means
How to recognize it
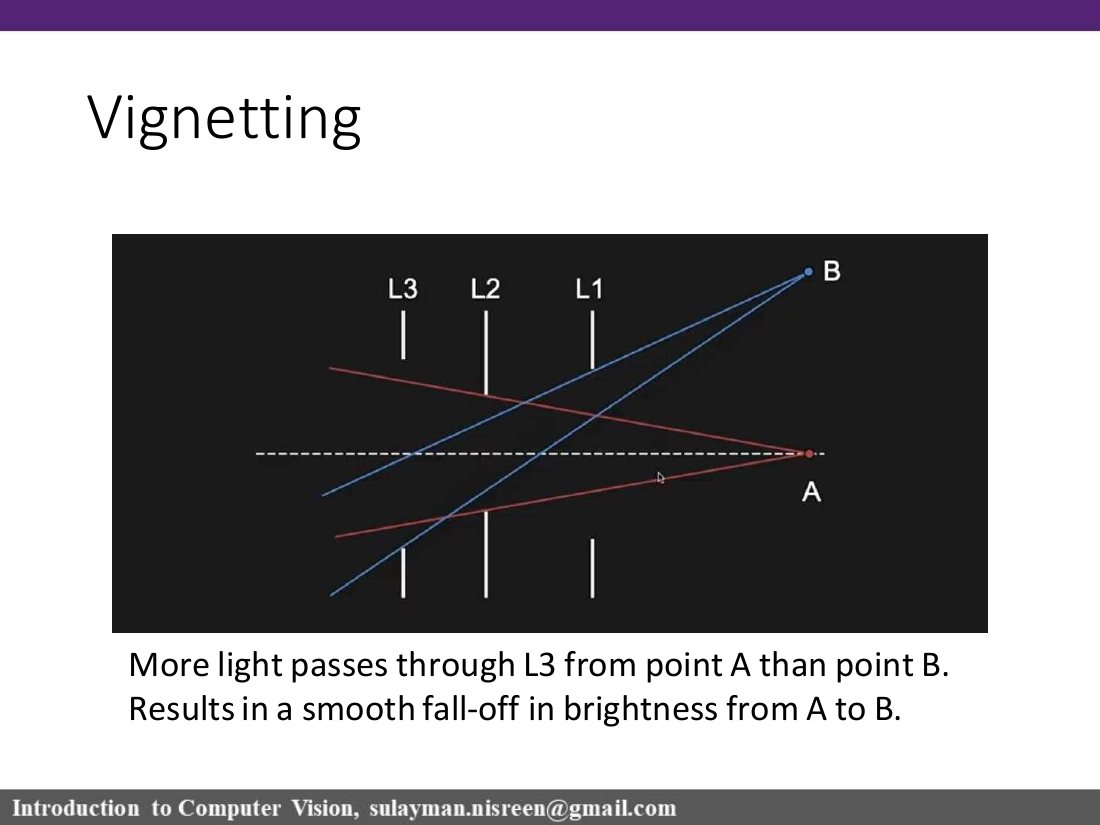
Vignetting
Less light reaches the image periphery than the center.
Image corners/edges look darker than the center.
Chromatic aberration
Refractive index depends on wavelength, so different colors focus at different distances.
Colored outlines/fringes near high-contrast object edges.
Geometric distortion
Straight scene lines bend in the image due to imperfect projection.
Barrel/pincushion-like warping.
Tangential distortion
Lens and image plane are not perfectly parallel.
Asymmetric distortion caused by misalignment.
Compound lenses
When the lecture asks "why compound lenses?", the answer is not only zoom. It is mainly correction: combine elements of different shapes/materials to reduce vignetting, chromatic aberration, and geometric distortion.
— Lecture 04 · Image Sensing
From optical images to digital numbers
من الصورة الضوئية إلى الأرقام الرقمية
Image sensing converts an optical image into a digital image so a computer can store, process, and analyze it.
Resolution: number of pixels in the image.
Noise: undesirable modifications to the image signal.
Dynamic range: range of brightness values that the sensor can measure.
Film: photochemical sensing
Black-and-white film has four layers: protective coat, gelatin with silver halide crystals, polymer film base, and anti-halation backing. Exposure creates a latent image: invisible after exposure, visible only after development.
الصورة الكامنة latent image هي صورة غير مرئية تتكوّن على الفيلم بعد التعريض وقبل التحميض.
Silicon sensors: photoelectric conversion
A photon with sufficient energy striking silicon creates an electron-hole pair. The sensor collects the generated charge, then electronics convert that charge into voltage and finally into digital numbers.
pixel-size example4912 × 3684 pixels on 6.14 mm × 4.6 mm → ≈ 1.25 μm / pixel
Once pixel size becomes comparable to the wavelength of light, making pixels smaller no longer improves true optical resolution; diffraction and optics become the limit.
CCD vs. CMOS sensors
Sensor
Core idea
Strength
Weakness
CCD
Each pixel stores charge in a potential well. Charges shift row by row in a "bucket brigade" to be converted at the edge.
High-quality charge handling.
Transfer is sophisticated and must avoid charge loss/unwanted charge.
CMOS
Each pixel includes its own circuit to convert electrons to voltage.
Flexible and common in consumer cameras.
Pixel circuit reduces the light-sensitive area per pixel.
How does a sensor measure color?
A bare pixel cannot know color; it only converts photons to electrons. To measure color, a color filter array places red, green, or blue filters over pixels. Since each pixel measures only one color, the missing channels are estimated by interpolation after capture.
البكسل لا يعرف لون الضوء وحده؛ لذلك نضع مرشحات ألوان فوق البكسلات ثم نستنتج القيم الناقصة بالاستيفاء.
— Lecture 04 · cont.
Noise in image sensors
الضجيج في مستشعرات الصورة
Noise is any unwanted modification of the signal during capture, conversion, transmission, processing, or storage. The lecture groups sensor noise into scene-dependent and scene-independent sources.
Noise type
Distribution / behavior
Cause
Depends on scene brightness?
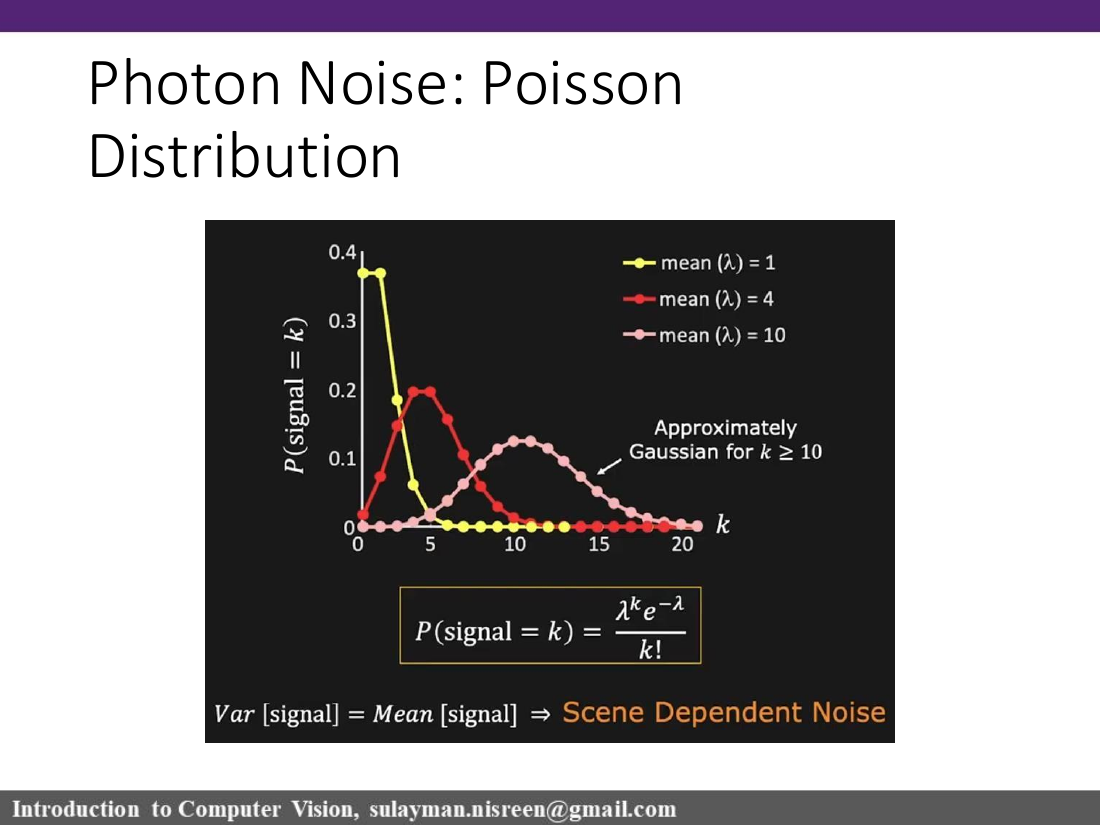
Photon shot noise
Poisson
Quantum nature of light and random photon arrivals.
Yes. Mean corresponds to scene brightness; variance increases with brightness.
Read noise
Gaussian
Electronics during electron-to-voltage conversion.
No. Depends on sensor quality.
Quantization noise
Rounding/discretization error
ADC maps analog voltage to an integer.
Mostly no.
Dark current noise
Thermal electrons
Electrons generated by sensor temperature even in darkness.
No.
Fixed-pattern noise
Pixel-to-pixel pattern
Manufacturing imprecision; no two pixels are identical.
No.
Poisson photon noiseP(k)=λᵏe⁻λ/k! , Var = Mean = λ
quantization noiseVar = Δ² / 12
Dark-frame subtraction
Take an image with the shutter closed, then subtract that dark frame from the noisy image. It reduces noise components that remain consistent from shot to shot: dark current and fixed-pattern noise. Use the same ISO and exposure time as the original photo.
— Lecture 05 · Binary Images
Binary images, thresholds, and moments
الصور الثنائية والعتبة والعزوم
A binary image has only two values: 0 or 1. It is easy to store, process, and analyze. A common way to create it is thresholding:
thresholdingb(x,y)=1 if f(x,y) ≥ T, else 0
نختار عتبة T: كل بكسل أعلى من العتبة يصبح 1، والباقي 0.
Image moments
Image moments are statistical parameters used to describe segmented objects. They give simple geometric properties such as area, centroid/position, and orientation.
area and centroidA = ∬ b(x,y)dxdy , x̄=∬xb/A , ȳ=∬yb/A
Area
For a binary object, area is the count/sum of foreground pixels.
Centroid
The object's center of mass: average x/y location of foreground pixels.
Orientation
The direction of the axis of least inertia, equivalent to the axis with least second moment.
Roundedness
A shape descriptor that distinguishes elongated objects from compact/circular ones by comparing minimum and maximum second moments.
For orientation, the lecture represents a line as:
line formx sin θ - y cos θ + ρ = 0
where θ is the line angle and ρ is the perpendicular distance from the line to the origin. The second moment E is the integral/sum of squared perpendicular distances from object points to the chosen axis; choose the axis that minimizes E.
orientation from momentstan(2θ)=b/(a-c) → θ = atan2(b,a-c)/2
with shifted coordinates x' = x - x̄, y' = y - ȳ, where a = ∬x'²b, b = 2∬x'y'b, and c = ∬y'²b. The orientation axis passes through the centroid.
Which θ?
The equation has two perpendicular solutions: θ₁ and θ₂ = θ₁ + π/2. One gives the minimum of E, the other gives the maximum. The lecture uses the second derivative test: if d²E/dθ² > 0, that axis is the minimum and therefore the object orientation; if it is < 0, it is the maximum.
Roundedness is close to 1 for compact/circular objects because spread is similar in every direction. It becomes smaller for elongated objects because the minimum and maximum moments differ strongly.
— Lecture 05 · cont.
Connected components, topology, and skeletons
المكوّنات المتصلة والطوبولوجيا والهياكل العظمية
Connected-component labeling
When a binary image has multiple objects, segment it into separate components by assigning labels to connected foreground pixels.
Region-growing algorithm
Find an unlabeled seed pixel with b = 1. If none exists, terminate.
Assign a new label to the seed.
Assign the same label to foreground neighbors.
Repeat for neighbors of neighbors until no unlabeled foreground neighbors remain.
Return to the first step.
Sequential labeling algorithm
Scan in raster order: left to right across each row, top to bottom. Assign a label based on already-scanned neighbors. If neighboring labels conflict, record their equivalence, then resolve equivalent labels in a later pass.
المسح النقطي raster scan يعني المرور على الصفوف من الأعلى للأسفل، وفي كل صف من اليسار إلى اليمين.
Neighborhood and connectedness
The meaning of "neighbor" matters. 4-connectedness uses the horizontal and vertical neighbors; 8-connectedness also includes diagonals. The lecture also mentions hexagonal tessellation as a 6-connected arrangement.
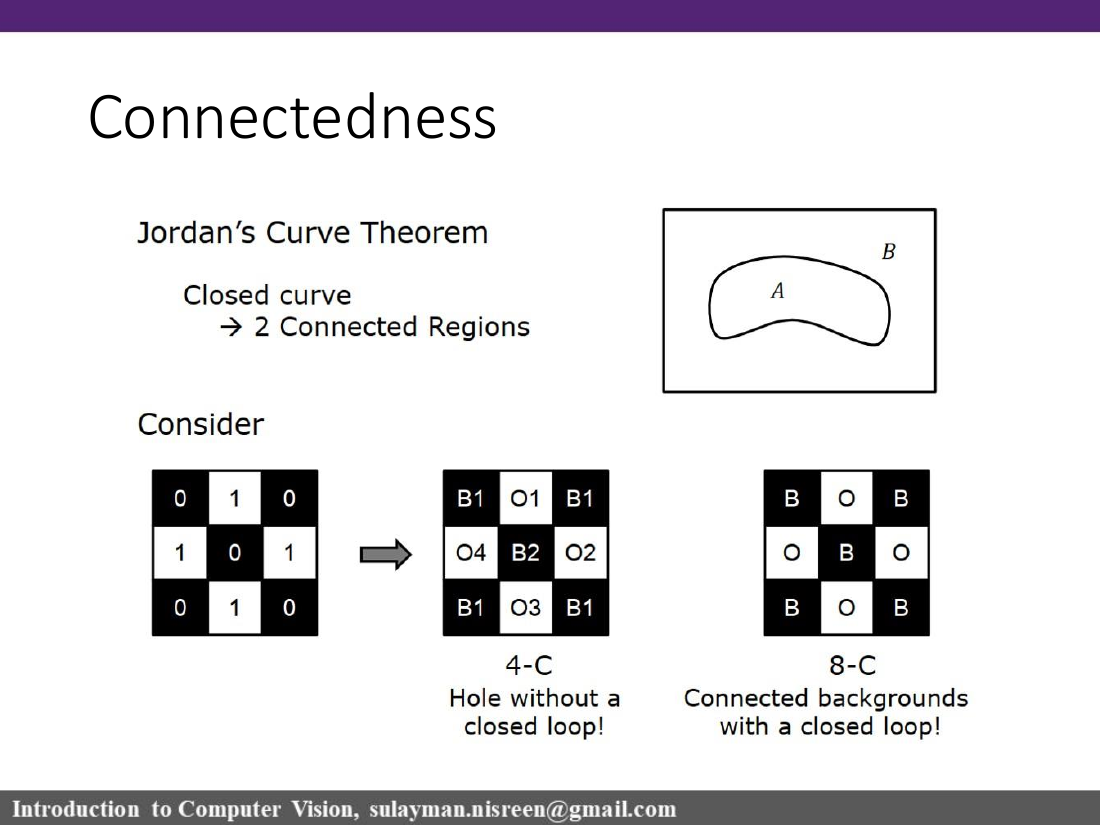
Connectedness ambiguity
4-connectedness and 8-connectedness are not just different choices; they create different topology. With diagonal contact, 8-connected foreground can merge objects that 4-connected foreground would keep separate. The lecture highlights the Jordan closed-loop ambiguity: deciding foreground/background connectedness inconsistently can create fake holes or broken boundaries. A 6-connected hexagonal grid avoids the diagonal ambiguity, and asymmetric schemes are another workaround.
Topology and Euler number
Topology studies shape properties preserved by stretching or bending, but not tearing or gluing. For binary shapes, the Euler number is commonly used as:
topologyE = number of components - number of holes
Skeletons
A skeleton is a simplified centerline representation of a binary shape. It preserves the essential structure while removing boundary thickness.
Shape simplification.
Feature extraction from vessels, nerves, roots, and similar structures.
Shape matching and handwriting recognition.
Path planning and navigation.
Topological analysis of biological networks.
— Lecture 06 · Image Processing I
Images as functions and convolution systems
الصورة كدالة والالتفاف
An image can be treated as a function f(x,y). Point processing applies a transformation T independently at each pixel to produce g(x,y). Examples include brightness/contrast changes and thresholding.
Why images become grainy or blurry
High ISO: amplifies the signal in low light and increases visible grain.
Low light: too few photons arrive, so noise becomes noticeable.
Small sensor/pixels: smartphone pixels collect fewer photons and are more noise-sensitive.
Blur: can come from defocus, motion, or smoothing operations.
Linear shift-invariant systems (LSIS)
An LSIS is both linear and shift invariant. In imaging, ideal lenses and many filters are modeled this way.
Property
Meaning
Lens intuition
Linearity
Scaling or adding inputs scales/adds outputs.
If scene brightness doubles, focused and defocused image brightness doubles.
Shift invariance
Shifting the input shifts the output by the same amount.
If an object shifts in the scene, its focused and defocused images shift similarly.
core theoremLSIS ⇔ convolution with an impulse response h
1D and discrete 2D convolutiong(x)=∫f(t)h(x-t)dt , g[i,j]=ΣₘΣₙ f[m,n]h[i-m,j-n]
convolution propertiesa*b=b*a , (a*b)*c=a*(b*c)
Commutativity lets you swap image/filter order mathematically. Associativity means cascaded filters can be combined first: filtering by b and then c is equivalent to one filter b*c.
The unit impulse or delta function leaves a function unchanged when convolved with it. The response of a system to an impulse is its impulse response. In imaging, this is called the point spread function (PSF): how a point source spreads on the image/retina.
unit impulse identitiesf * δ = f , δ * h = h
دالة الانتشار النقطي PSF تصف كيف تتحول نقطة ضوئية مثالية إلى بقعة موزعة بسبب النظام البصري.
Discrete 2D convolution
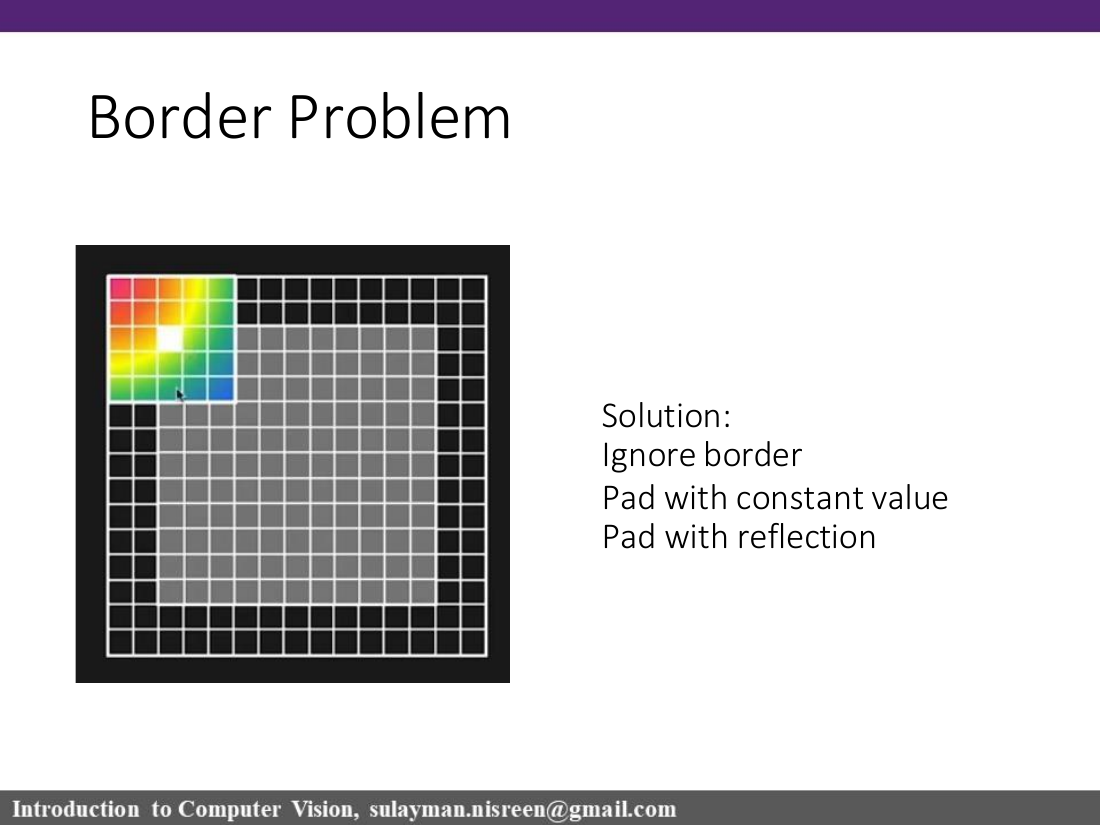
Convolution with discrete images slides a kernel over the image and computes weighted sums. Borders are a practical issue: common solutions are ignoring borders, padding with a constant value, or padding by reflection.
Gaussian smoothing is separable: a 2D Gaussian filter can be applied as a 1D horizontal filter followed by a 1D vertical filter. For a K×K kernel, direct 2D convolution costs about K² multiplications per pixel; separable filtering costs about 2K.
Gaussian vs. bilateral
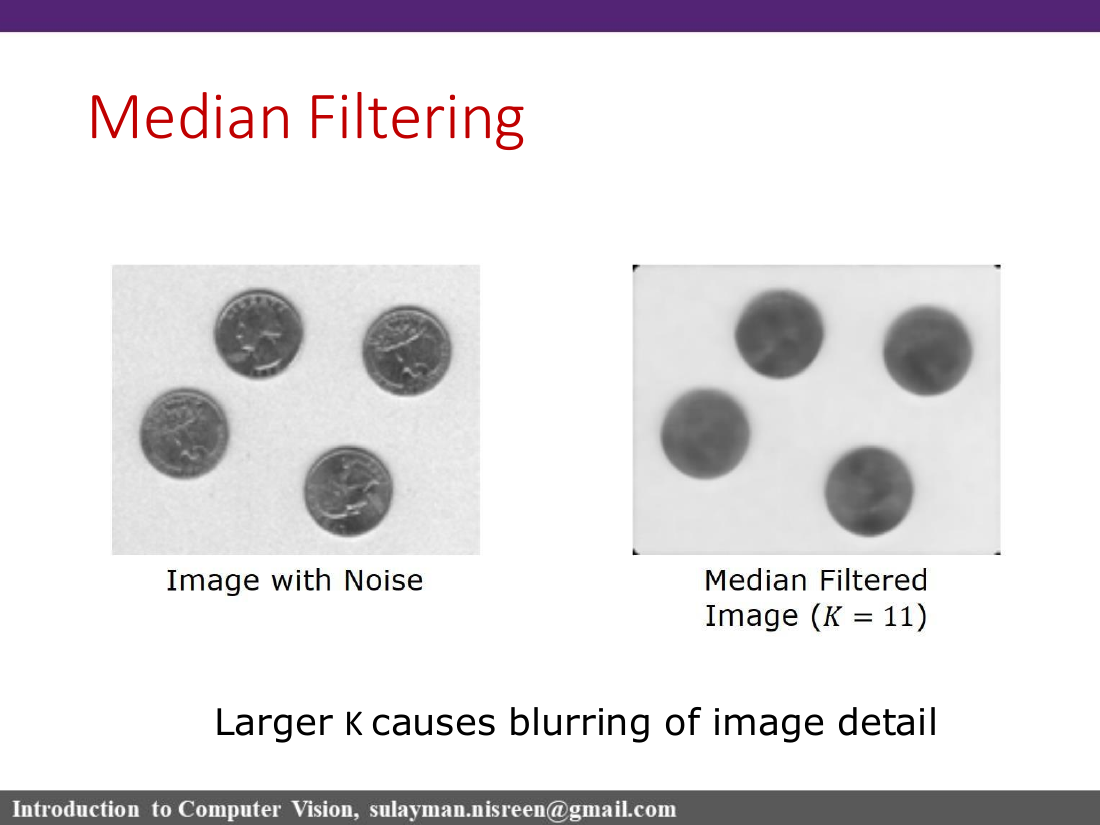
A Gaussian filter uses the same spatial kernel everywhere and blurs across edges. A bilateral filter reduces weights for pixels whose intensities differ from the center pixel, so it avoids mixing across strong edges.
The first Gaussian measures spatial closeness; the second measures intensity similarity. That second term is why bilateral filtering is nonlinear and edge-preserving. Small intensity sigma rejects cross-edge pixels strongly; very large intensity sigma makes the intensity term nearly constant, so the filter behaves much more like ordinary Gaussian smoothing.
— Lecture 07 · Frequency Domain
Fourier transform and frequency-domain filtering
تحويل فورييه والترشيح في المجال الترددي
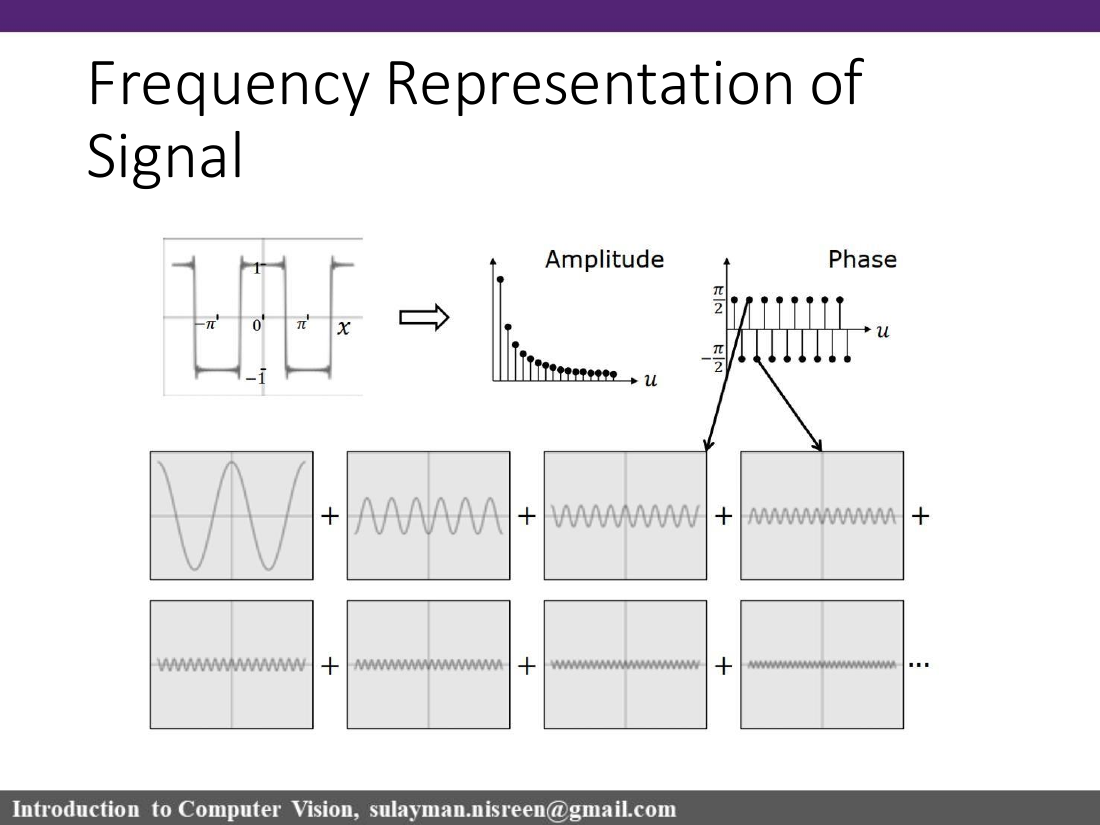
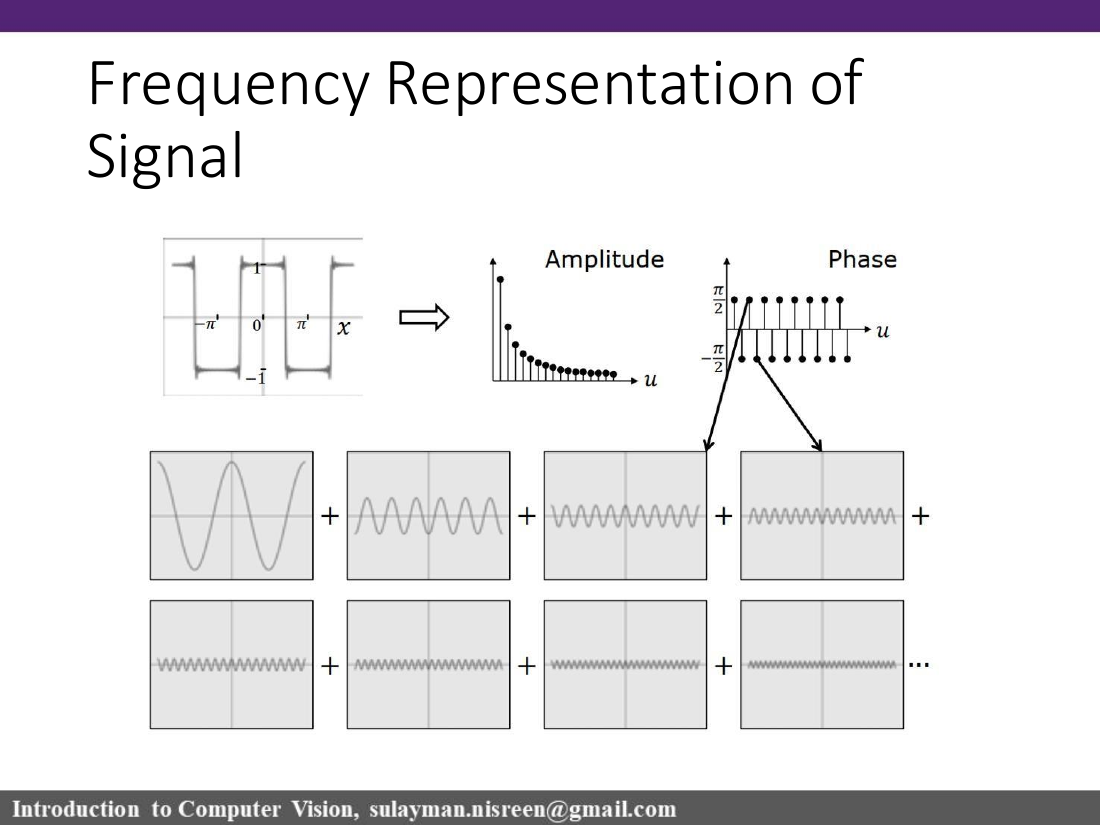
The Fourier idea: a signal or image can be understood by asking which sinusoidal frequencies are inside it. The spatial domain asks "what value is at this pixel/location?"; the frequency domain asks "which frequencies are present, with what amplitude and phase?"
المجال المكاني يصف الصورة حسب المكان. المجال الترددي يصفها حسب الترددات: ما مقدار كل موجة جيبية داخل الصورة؟
sinusoidf(x)=A sin(2πux+φ)
A is amplitude, u is frequency, and φ is phase. Higher frequency means faster oscillation: in images, this usually means fine detail, edges, texture, or noise.
From Fourier series to Fourier transform
The lecture builds intuition with Fourier series: a square wave can be approximated by adding sinusoids. More terms add sharper edges. The Fourier Transform generalizes this idea from periodic sums to a continuous frequency representation.
Euler formulaeiθ = cos θ + i sin θ
The sinusoids are inside the complex exponential. The Fourier coefficient captures both amplitude and phase, so the Fourier transform is generally complex.
1D FT / IFTF(u)=∫f(x)e-i2πuxdx , f(x)=∫F(u)ei2πuxdu
Displayed spectra usually show log(|F|), because the DC/low-frequency values can dominate so strongly that weaker frequency components would otherwise be invisible.
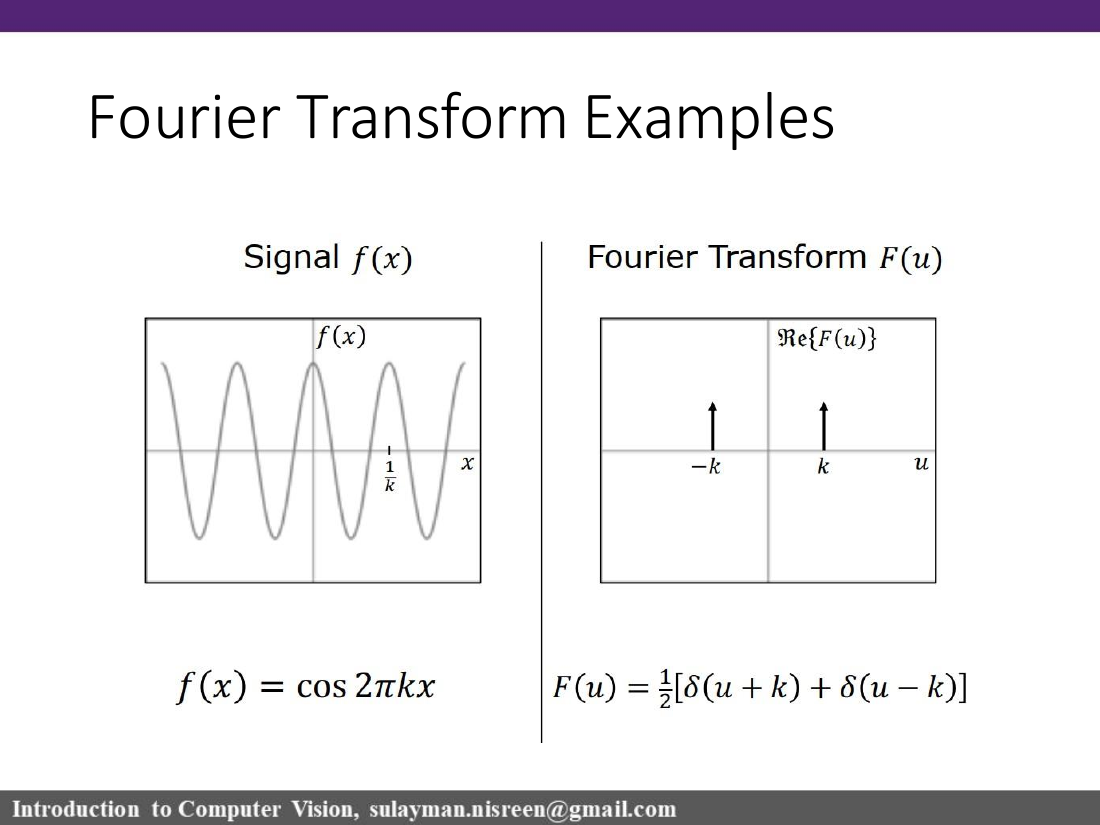
Transform pairs to recognize
Spatial signal
Frequency-domain result
Exam memory
constant f(x)=1
impulse at zero frequency, δ(u)
all energy is DC / average brightness.
delta δ(x)
flat spectrum, F(u)=1
a perfect point contains all frequencies.
cos(2πkx)
two impulses at u=±k
one pure frequency appears as symmetric peaks.
rectangle Rect(x/T)
T sinc(Tu)
sharp spatial edges produce wide frequency tails.
Gaussian
Gaussian
Gaussian smoothing is special in both domains.
Fourier Transform properties
Property
Formula idea
Meaning
Linearity
αf₁+βf₂ ⇔ αF₁+βF₂
weighted sums stay weighted sums.
Scaling
f(ax) ⇔ (1/|a|)F(u/a)
compressing in space spreads in frequency.
Shifting
f(x-a) ⇔ e-i2πuaF(u)
spatial shift changes phase, not magnitude.
Differentiation
dⁿf/dxⁿ ⇔ (i2πu)ⁿF(u)
derivatives emphasize high frequencies.
Convolution theorem
The important connection with Lecture 6 is two-way:
convolution theorem ★f*h ⇔ F·H , f·h ⇔ F*H
Practically, large convolutions can be computed through FT: transform the image and filter, multiply their spectra, then apply IFT. Conceptually, this also explains filtering: a blur kernel is a frequency mask that suppresses high frequencies.
frequency filtering workflowimage → FT → multiply by filter spectrum → IFT → filtered image
Gaussian smoothing in frequency space
Spatial view: convolve the signal/image with a Gaussian kernel. Frequency view: multiply the spectrum by a Gaussian low-pass. High-frequency noise/details shrink; low frequencies remain, so the output becomes smoother.
2D Fourier transform for images
Images have horizontal and vertical frequencies. Low frequencies describe smooth, slowly varying intensity; high frequencies describe rapid changes such as edges, texture, and noise.
2D FT / IFTF(u,v)=∬f(x,y)e-i2π(ux+vy)dxdy , f(x,y)=∬F(u,v)ei2π(xu+yv)dudv
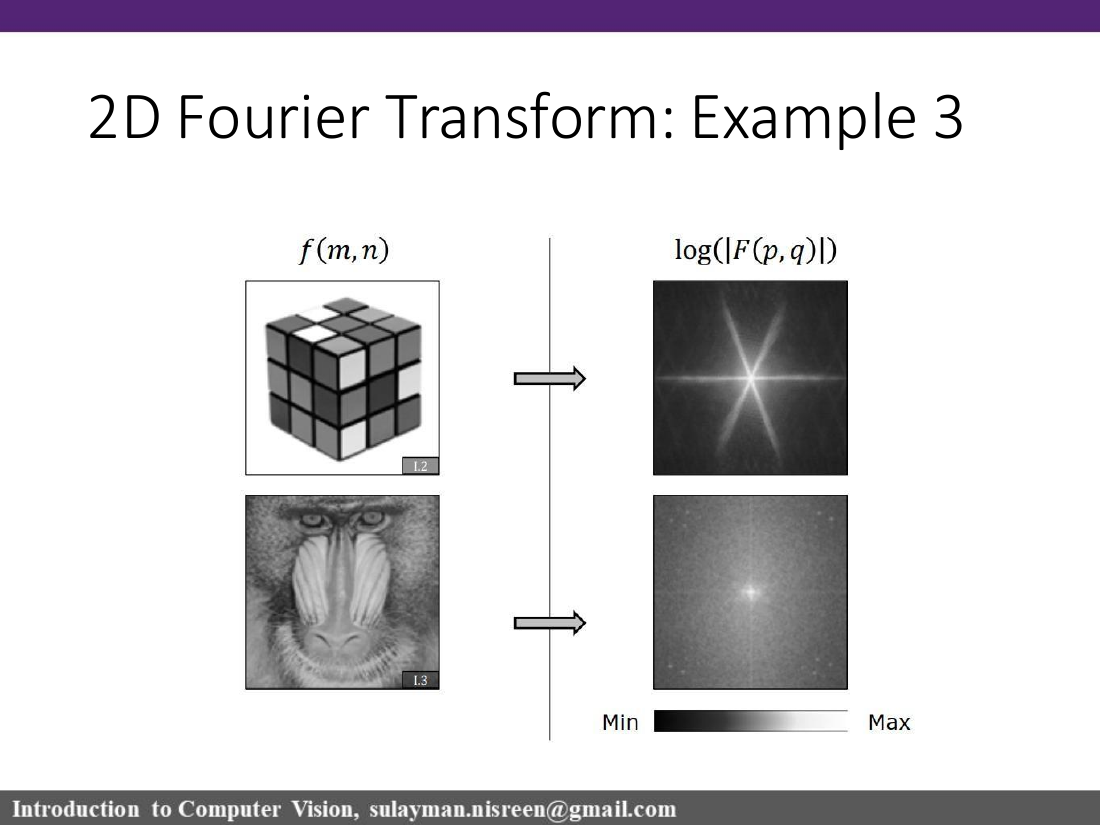
In the usual centered display, the middle is low frequency/DC. Bright dots away from the center indicate repeating sinusoidal patterns. Vertical stripes in the image create horizontal frequency peaks; more stripes means peaks farther from the center. Natural photos concentrate energy near low frequencies, while random noise spreads energy broadly.
Filter
Keeps
Removes
Visual effect
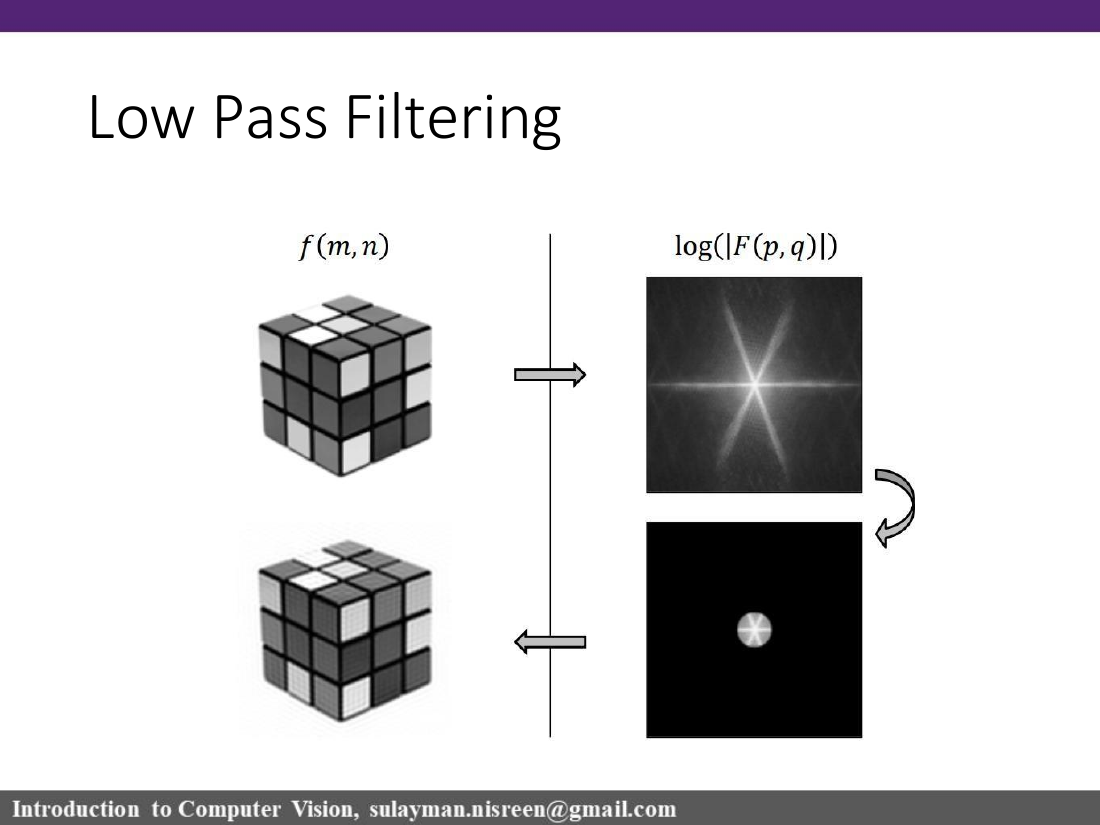
Low-pass
Low frequencies
High frequencies
Smoothing / blur / noise reduction.
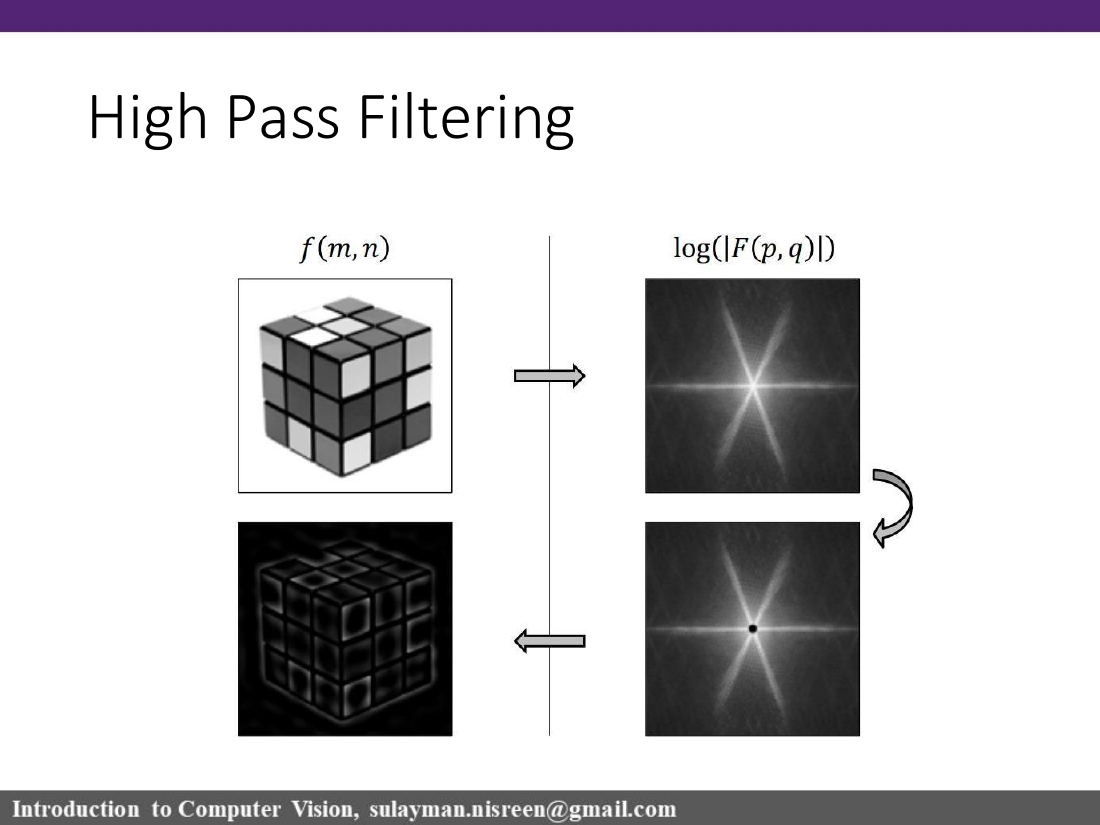
High-pass
High frequencies
Low frequencies
Edges and fine details emphasized.
Gaussian smoothing
Low frequencies with soft roll-off
High frequencies gradually
Natural blur without harsh ringing.
الترددات المنخفضة تمثل التغيّر البطيء في الصورة، أما الترددات العالية فتمثل الحواف والتفاصيل والضجيج.
— Personal Memory Lab
يا كتكووت :v visual stories
قصص بصرية سريعة يا كتكووت لتثبيت الأفكار الصعبة
How to use this page
This section turns the most exam-heavy ideas into small stories. Read the picture first, then say the formula out loud, then answer the “يا كتكووت” prompt in one sentence.
🐥يا كتكووت: كل صورة هنا مثل لقطة صغيرة في رأسك. تشوفيها، تبتسمي، وبعدين تقولي: آه، هذا القانون أعرف قصته.
الفكرة هنا: اربطي كل قانون بصورة قصيرة. عندما يظهر القانون في الامتحان، ارجعي للقصة البصرية ثم اكتبي المعنى.
The rule: if you can explain it from the picture in ten seconds, you probably understand it well enough to solve a question.
يا كتكووت
Pinhole vs. lens: the brightness-sharpness story
🐣يا كتكووت: تخيّلي إنك ماسكة صندوق كاميرا صغير. أول ثقب يقول لك: “أنا حاد بس نعسان، ضوئي قليل.” الثقب الكبير يقول: “أنا منوّر بس أخربط الصورة.” فتجي العدسة وتقول: “ولا يهمك، أجيب ضوء كثير وأرتبه في نقطة واحدة.”
Memory line: tiny hole = sharp but dim; big hole = bright but blurry; lens = bright and sharp when focused.
When a pinhole question appears, do not start with equations. Start with rays: one narrow ray is easy to keep sharp but carries little light; many unfocused rays are bright but smear; a lens is the useful trick because it accepts many rays and focuses them back together.
Pinhole: few rays → sharp but dim → needs long exposure.
Big hole without lens: many rays → bright but blurry because each scene point spreads.
Convex lens: many rays + refraction → focused point → bright and sharp when the sensor is at the right distance.
يا كتكووت
Binary shapes: from “gray mess” to measurements
🐥يا كتكووت: الصورة الرمادية داخلة الامتحان وهي متلخبطة. تحطي العتبة T كأنها بوابة: اللي يعبر يصير 1، واللي ما يعبر يصير 0. بعدها تبدئي تقيسي: وين القلب؟ بأي اتجاه مائلة؟ هل هي مدوّرة ولا ممدودة؟
Memory line: threshold first, then moments; moments are the measuring tape of a binary object.
The binary chapter is a recipe. First choose a threshold, then the object becomes a mask, then moments turn the mask into numbers: area, centroid, orientation, roundedness, and connected components.
Threshold: pixels above or below T become foreground/background.
Moments: summarize where the pixels are and how they spread.
Shape: roundness = small spread direction divided by large spread direction.
يا كتكووت
Fourier: image ingredients instead of pixels
🐣يا كتكووت: فورييه يقول لكِ: “لا تنظري للصورة كبكسلات فقط، اسمعي موسيقاها.” التغيّر الهادئ صوت منخفض في الوسط، الحواف نقرات أسرع، والضجيج رشّات صغيرة في الأطراف.
Memory line: center of spectrum = smooth/slow changes; outside = edges, texture, noise.
Spatial domain asks “what is the pixel here?” Fourier asks “which waves built this picture?” Smooth lighting sits near the center of the spectrum. Edges, details, texture, and noise move outward toward higher frequencies.
Story: you move the object away from the camera, so z₀ gets bigger and the image shrinks. Bigger focal length is like zooming in, so the image grows.
Thin lens
1/f = 1/o + 1/i
Story: object distance and image distance must balance the lens. If one side changes, focus moves on the other side.
f-number
N = f / D
Story: bigger N means smaller aperture diameter D. So f/32 is not “more open”; it is a smaller opening than f/5.6.
Photon shot noise
σ ≈ √N, SNR ≈ √N
Story: light arrives randomly. If you collect more photons, signal grows faster than uncertainty, so bright images look cleaner.
Centroid
x̄ = M₁₀/M₀₀, ȳ = M₀₁/M₀₀
Story: the centroid is the balancing point of the white pixels. M₀₀ is area; M₁₀ and M₀₁ are weighted sums.
Convolution theorem
f * h ⇔ F · H
Story: sliding a filter in the image world becomes multiplying masks in the frequency world.
One-minute exam rehearsal
Before solving a problem, classify it into one of three worlds: geometry means rays, projection, focus; binary shape means threshold, moments, components; filtering means convolution, smoothing, Fourier, low-pass/high-pass.
Geometryrays · f · z · focus
ShapeT · moments · labels
Filteringkernel · noise · frequency
— Diagram Memory Palace
Slide visual atlas
أطلس بصري لأهم مخططات المحاضرات
Use this section as a fast visual review. The images are rendered from the lecture slides and paired with the exact idea to remember.
Lectures 1-2 visuals: perception and pinhole geometry
Checker shadow
Equal pixel brightness can look different because vision interprets illumination context.
Kanizsa triangle
The brain completes missing contours; seeing is interpretation, not raw measurement.
Projection equations
The core pinhole result: image position scales by focal length and divides by depth.
Vanishing point
Parallel 3D lines meet at the projection of their shared direction vector.
frequency representation stores amplitude and phase.
FT pairs
constant→δ · δ→flat rect→sinc · Gaussian→Gaussian
pure sinusoids produce symmetric frequency peaks.
FT properties
linear · scale · shift · derivative
shifts affect phase; differentiation emphasizes high frequencies.
Convolution theorem
f*h ⇔ F·H f·h ⇔ F*H
use FT filtering by transform → multiply → inverse transform.
2D DFT
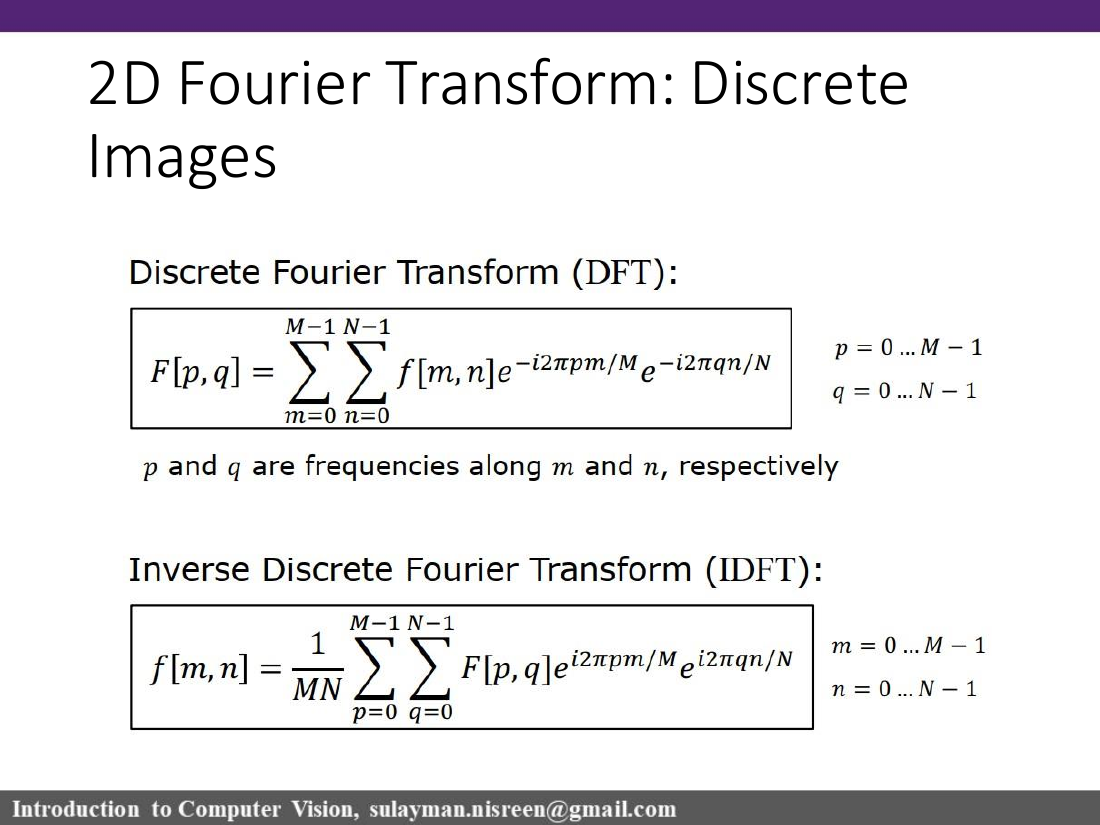
F[p,q]=ΣΣf[m,n]e⁻ⁱ²πpm/M e⁻ⁱ²πqn/N
IDFT has the 1/(MN) normalization.
Frequency filters
low-pass blur high-pass edges
in centered spectrum displays, the center is low frequency / average brightness.
— Part VIII · Test yourself
Practice Questions
أسئلة تطبيقية للاختبار النهائي
Click each question to reveal a model answer. Try to answer in your head first — the friction is the point.
Q · 01
State three one-line definitions of computer vision.
(1) Automating human visual processes. (2) An information-processing task. (3) Inverting image formation — recovering useful scene information from the 2D image, sometimes including 3D structure.
Q · 02
Give three reasons to build artificial vision systems even though humans see so well.
(1) Free up human time for more rewarding activities. (2) Human vision is poor at precise measurement of physical-world quantities. (3) Machines can surpass human vision and extract information we cannot perceive (e.g. infrared, X-ray, satellite, microscopy).
Q · 03
Name the four stages of a typical computer-vision pipeline, with one example operation per stage.
(1) Pre-processing — noise reduction. (2) Selecting areas of interest — object detection / segmentation. (3) Precise processing of selected areas — recognition or tracking. (4) Decision making — match/no-match, motion analysis, flagging events.
Q · 04
Define pinhole, optical axis, and effective focal length.
Pinhole: an opaque sheet with a tiny hole in it. Optical axis: the axis perpendicular to the image plane, passing through the pinhole. Effective focal length f: the distance between the pinhole and the image plane.
Q · 05
Derive the perspective projection equations from similar triangles.
Place origin at the pinhole. The ray from scene point P₀ = (x₀, y₀, z₀) to image point Pᵢ = (xᵢ, yᵢ, f) passes through the origin, so the two position vectors are parallel: r̄ᵢ / f = r̄₀ / z₀. Component-wise: xᵢ/f = x₀/z₀ and yᵢ/f = y₀/z₀. Solving: xᵢ = f·x₀/z₀, yᵢ = f·y₀/z₀.
Q · 06
A camera has focal length f = 50 mm. An object is at depth z₀ = 5 m. What is the magnification? If the object is 20 cm tall, how tall is its image?
Convert: f = 0.05 m, z₀ = 5 m. Magnification m = f/z₀ = 0.05/5 = 0.01 (or 1/100). Image height = 0.01 × 20 cm = 0.2 cm = 2 mm. (Sign convention: m is negative because the image is inverted, but we usually report |m|.)
Q · 07
A 3D line has direction vector ⟨lₓ, l_y, l_z⟩ = ⟨1, 0, 2⟩ with f = 50 mm. Where is its vanishing point?
(x_vp, y_vp) = (f·lₓ/l_z, f·l_y/l_z) = (50·1/2, 50·0/2) = (25 mm, 0). The point lies on the x-axis of the image plane.
Q · 08
Why does the image get blurry both when the pinhole is too large and when it is too small?
Too large: the hole admits a bundle of rays from each scene point, spreading them into a disk on the image — geometric blur. Too small: the hole acts as a slit and the wave nature of light causes diffraction, spreading the light into rings on the image — diffraction blur. The optimum balances both: d ≈ 2·√(f·λ).
Q · 09
A pinhole camera has f = 100 mm and uses green light, λ ≈ 550 nm. What is the ideal pinhole diameter?
Convert: f = 0.1 m, λ = 550 × 10⁻⁹ m = 5.5 × 10⁻⁷ m. f·λ = 5.5 × 10⁻⁸ m². √(f·λ) ≈ 2.35 × 10⁻⁴ m = 0.235 mm. d ≈ 2 × 0.235 ≈ 0.47 mm.
Q · 10
If a pinhole camera gives sharp images at the optimal hole size, why do we need lenses at all?
Because at the optimal (tiny) hole size, very little light reaches the image, so exposure times become impractically long — the lecture's example is 12 seconds for a still building. Anything moving will blur, and handheld photography is impossible. A lens can be physically large (gathering much more light) while still focusing all rays from one scene point onto one image point. We get both brightness and sharpness.
Q · 11
What is a vanishing point, and what determines its location in the image?
The vanishing point of a family of parallel 3D lines is the single image point at which they appear to converge. Its location depends entirely on the orientation (direction vector) of those parallel lines in 3D — not on where the lines themselves are. Formally: (x_vp, y_vp) = (f·lₓ/l_z, f·l_y/l_z) where ⟨lₓ, l_y, l_z⟩ is the shared direction.
Q · 12
Why is "training a neural net on tons of data" not always the best approach for a computer-vision problem?
(1) Unnecessary: many phenomena (e.g. perspective projection, lens optics) are described exactly from first principles — training is overkill. (2) Diagnosability: when a network fails, first principles are the only path to understanding why. (3) Data efficiency: first-principles models can synthesize training data instead of collecting it laboriously.
Q · 13
What does the projection of a 3D straight line onto the image plane look like? Justify.
It's a 2D straight line. Reason: a 3D line plus the pinhole (origin) defines a plane in 3D. The intersection of that plane with the image plane is a line. Therefore straight lines in the scene always map to straight lines in the image.
Q · 14
Explain the Checker Shadow illusion in one paragraph.
Two checkerboard squares A and B have the same pixel brightness, but B looks brighter than A because B sits inside the cast shadow of a cylinder. The visual system "discounts" the shadow — it interprets B as a light square that happens to be in shade, and A as a dark square in full light. The illusion shows that perceived brightness depends on inferred illumination, not raw pixel values — a useful warning that vision involves interpretation, not just measurement.
Q · 15
An object of area 100 cm² is imaged with magnification m = 0.05. What is the image area?
Area magnification = m² = 0.05² = 0.0025. Image area = 0.0025 × 100 cm² = 0.25 cm² = 25 mm².
Q · 16
Name the four sub-areas of Computer Vision in their canonical order.
(1) Imaging, (2) Features and boundaries, (3) 3D reconstruction, (4) Visual perception. The order matters: each builds on the previous — you need an image before you can detect features, features before you can reconstruct 3D, and reconstructed structure before high-level perception.
Q · 17
Match the brain region to its function: V1, V5/MT, V8, LO, LGN.
LGN — relay from retina to cortex. V1 — primary visual cortex, receives all visual input, smallest receptive fields, begins color/motion/shape processing. V5/MT — motion detection. V8 — color processing. LO — recognition of large-scale objects. (Bonus: V3A is also motion-biased; V4v and V7 functions are unknown; V6 only confirmed in monkeys.)
Q · 18
What are the three components of a computer vision system, and what is the output?
Components: (1) Camera — captures the scene. (2) Lighting — illuminates the scene; without controlled lighting, vision is unreliable. (3) Vision software — processes the captured image. The output is a scene description — a structured representation of what is in the scene (objects, positions, attributes). The scene itself is the input.
Q · 19
State the three things "Vision Research" tells us about the field.
(1) Vision is a hard problem. (2) Vision is multi-disciplinary — combining AI, machine learning, optics, robotics, NLP, image preprocessing, and domain knowledge. (3) Considerable progress has been made, with many successful real-world applications.
Q · 20
A pixel in an image can carry which four kinds of value?
Brightness, color, distance (depth), material. The first two are standard in any RGB image; depth requires a depth sensor (like Kinect's IR-projector + IR-camera combo); material is inferred from reflectance properties or specialized sensors (e.g. hyperspectral).
Q · 21
A thin lens has f = 50 mm and an object distance o = 300 mm. Find the image distance i.
Use 1/f = 1/o + 1/i. So 1/i = 1/50 - 1/300 = 6/300 - 1/300 = 5/300 = 1/60. Therefore i = 60 mm.
Q · 22
Why does a lens solve the pinhole camera's exposure problem?
A pinhole must be tiny to be sharp, so it gathers little light. A lens can be physically large, gathering much more light, while bending rays from one scene point so they meet at one image point. It gives brightness and sharpness together.
Q · 23
Define aperture and f-number. Which is brighter: f/5.6 or f/32?
Aperture D is the clear light-gathering opening of the lens. f-number N = f/D. f/5.6 is brighter because it has a larger aperture than f/32. f/32 is smaller, darker, and gives deeper depth of field.
Q · 24
What is depth of field, and how does aperture affect it?
Depth of field is the range of object distances that are acceptably focused, often meaning the blur circle is smaller than pixel size c. Smaller aperture (larger f-number) increases DoF but darkens the image. Larger aperture decreases DoF but brightens the image.
Q · 25
List four lens defects and the visual symptom of each.
A sensor is 6.14 mm wide and has 4912 pixels across. Estimate the pixel pitch.
Pixel pitch = 6.14 mm / 4912 ≈ 0.00125 mm = 1.25 μm.
Q · 27
Compare CCD and CMOS sensors in one paragraph.
In a CCD, each pixel stores charge and charges are shifted row by row like a bucket brigade to a common readout, then converted to voltage and digital output. In CMOS, each pixel includes local electron-to-voltage circuitry, making CMOS flexible and common in consumer cameras, but reducing the light-sensitive area in each pixel.
Q · 28
How does a camera sensor measure color if a pixel only counts photons?
It uses red, green, and blue filters above pixels, often in a Bayer-like pattern. Each pixel measures only one filtered color, then the missing color channels at each location are estimated by interpolation.
Q · 29
Match the noise type to its distribution: photon shot noise, read noise, quantization noise.
What is dark-frame subtraction and what noise does it reduce?
Capture a dark frame with the shutter closed, using the same ISO and exposure time as the real image, then subtract it from the real image. It reduces stable dark current and fixed-pattern noise.
Q · 31
Define a binary image and give the thresholding rule.
A binary image has only two values, 0 and 1. Thresholding converts grayscale f(x,y) to b(x,y): set b=1 if f(x,y) ≥ T, otherwise b=0.
Q · 32
What do zeroth, first, and second moments describe in a binary object?
Zeroth moment: area or total foreground mass. First moments: centroid/position. Second moments: spread/inertia and orientation of the object.
Q · 33
How is object orientation defined using the second moment?
Orientation is the axis of least inertia, i.e. the axis that minimizes the second moment E = ∬r²b(x,y)dxdy. The axis passes through the centroid. With shifted moments, θ₁ = atan2(b, a-c)/2 and the other solution is θ₂ = θ₁ + π/2. Use the second derivative test to choose the minimum.
Q · 34
Describe connected-component labeling by region growing.
Find an unlabeled foreground seed pixel b=1, assign a new label, label all connected foreground neighbors and neighbors of neighbors until the region stops growing, then repeat with the next unlabeled seed.
Q · 35
What is the Euler number of a binary image region with 3 bodies and 2 holes?
Euler number E = bodies - holes = 3 - 2 = 1.
Q · 36
What is skeletonization and why is it useful?
Skeletonization thins a binary shape to its medial/centerline structure while preserving topology. It is useful for shape simplification, feature extraction, recognition, path planning, and topology analysis.
Q · 37
Define a linear shift-invariant system and explain why it matters in image processing.
Linearity means scaled/summed inputs produce scaled/summed outputs. Shift invariance means shifting the input shifts the output the same way. LSIS matters because LSIS filters are exactly modeled by convolution with an impulse response.
Q · 38
What is the point spread function (PSF)?
The PSF is the impulse response of an imaging system: it describes how an ideal point source is spread into a pattern on the image/retina. It gives a complete local description of image quality for that system.
Q · 39
Why does a 5×5 all-ones averaging kernel saturate the image, and how do we fix it?
The kernel sum is 25, so it multiplies local brightness instead of averaging. Normalize it by using all entries 1/25 so the kernel sum is 1.
Q · 40
Compare Gaussian, median, and bilateral filtering.
Gaussian: linear weighted blur, good general smoothing but blurs edges. Median: nonlinear, chooses median, good for salt-and-pepper noise. Bilateral: nonlinear, weights by spatial closeness and intensity similarity, preserving edges better.
Q · 41
Why is Gaussian smoothing separable?
A 2D Gaussian can be factored into a product of a horizontal 1D Gaussian and a vertical 1D Gaussian. So a K×K convolution can be done as two cheaper 1D convolutions: about K² multiplications per pixel becomes about 2K.
Q · 42
Define Fourier Transform and Inverse Fourier Transform conceptually.
The Fourier Transform converts a spatial/time signal into a frequency representation showing which sinusoids are present and with what amplitude/phase. The inverse transform reconstructs the original signal from those frequency components.
Q · 43
Why is the Fourier Transform complex?
The FT uses complex exponentials e^(iθ)=cosθ+i sinθ. Each Fourier coefficient has real and imaginary parts, which encode magnitude/amplitude |F| and phase φ. Magnitude = √(Re²+Im²), phase = atan2(Im,Re).
Q · 44
State the convolution theorem and its practical use.
Convolution in the spatial domain corresponds to multiplication in the frequency domain: f*h ⇔ F·H. The reverse dual also appears: spatial multiplication corresponds to frequency convolution, f·h ⇔ F*H. Practically, transform the image and kernel, multiply spectra, then inverse-transform to get the filtered image.
Q · 45
In a 2D image spectrum, what do low-pass and high-pass filters do?
In the usual centered spectrum display, low-pass filters keep the center/low frequencies and suppress high frequencies, producing smoothing or blur. High-pass filters suppress the center/low frequencies and keep high frequencies, emphasizing edges, texture, and fine detail.
Q · 46
For Lecture 3, what magnification convention should you use for a thin lens?
Use the lecture convention: m = hᵢ/h₀ = i/o. Some optics texts add a negative sign to mark inversion, but the slides use the positive ratio.
Q · 47
Write the boxed closed-form depth-of-field equation from the lens lecture.
o₂ - o₁ = 2of²cN(o-f) / (f⁴ - c²N²(o-f)²). Here c is acceptable blur size, N is f-number, o is focused object distance, and f is focal length.
Q · 48
What happens if you block part of a focused lens?
The whole image becomes dimmer more than simply cropped. Many rays from each scene point pass through different parts of the lens and still focus to the same image point, so blocking part of the lens reduces the ray bundle/brightness.
Q · 49
Define roundedness using second moments.
Roundedness = E_min / E_max, where E_min = E(θ₁) and E_max = E(θ₂). Values near 1 indicate similar spread in all directions; smaller values indicate elongated shapes.
Q · 50
Why can 4-connectedness and 8-connectedness change the topology of a binary image?
They disagree about diagonal contact. 8-connected foreground may merge diagonal pixels into one object; 4-connected foreground may keep them separate. This can also change whether a boundary is closed and whether a hole exists. Hexagonal 6-connectedness avoids the diagonal ambiguity.
Q · 51
State the two convolution properties emphasized in Lecture 6 and why they matter.
Commutative: a*b = b*a. Associative: (a*b)*c = a*(b*c). Associativity means cascaded filters can be combined into one equivalent filter before applying them to the image.
Q · 52
What are the unit impulse identities for convolution?
f * δ = f and δ * h = h. The system response to an impulse is the impulse response h; in imaging this is the point spread function.
Q · 53
How does the bilateral filter change when the intensity sigma becomes very large?
The intensity-similarity term becomes nearly constant, so the bilateral filter loses much of its edge-preserving behavior and approaches ordinary Gaussian spatial smoothing.
Q · 54
For the sinusoid f(x)=A sin(2πux+φ), identify A, u, and φ.
A is amplitude, u is frequency, and φ is phase. Higher u means faster oscillation, which corresponds to finer spatial detail in images.
Q · 55
Match these Fourier transform pairs: constant, delta, rectangle, Gaussian.
Constant → impulse at zero frequency. Delta → flat spectrum. Rectangle → sinc. Gaussian → Gaussian. A pure sinusoid gives symmetric peaks at ± its frequency.
Q · 56
State four Fourier Transform properties and one exam meaning for each.
Linearity: sums transform to sums. Scaling: compression in space spreads frequency. Shifting: spatial shift changes phase but not magnitude. Differentiation: multiplies by powers of frequency, emphasizing high frequencies.
Q · 57
Write the 2D DFT/IDFT normalization fact that is easy to forget.
The forward DFT sums over m=0..M-1 and n=0..N-1. The inverse DFT reconstructs f[m,n] and includes the normalization factor 1/(MN).
Q · 58
How do you interpret common 2D spectrum patterns?
In a centered spectrum, the center is DC/low frequency. Bright off-center dots indicate repeating sinusoidal patterns. Vertical stripes in the image create horizontal frequency peaks; more stripes push peaks farther out. Random noise spreads energy broadly.